


POC pour obtenir votre IA privée et gratuite avec Jan, HuggingFace et PrivateGPT
Cet article fait suite à mon premier article sur un déploiement analogue mais dont la technologie de base, pour fournir le modèle LLM sur un serveur localhost, c’est à dire un serveur d’inférence local, n’était pas conforme à mes attentes en terme de licence d’utilisation. Il s’agissait en effet de LM Studio dont la licence propriétaire est très restrictive en juin 2024 !
Ici nous allons créer ce POC avec Jan qui est distribué gracieusement sous licence Open Source AGPLv3. https://jan.ai/
Je pars du principe que vous avez suivi mon premier article, à minima pour les explications théoriques et les outils de base nécessaires à la construction de ce POC. Sinon je vous invite grandement à le faire si vous n’avez pas déjà les compétences requises dans ce domaine !
Technologies nécessaires pour ce POC
- Plateforme Apple macbook Pro M2 MAX avec 32 Go de mémoire vive.
- Homebrew comme gestionnaire de paquets pour le système d’exploitation macOS.
- iTerm2 comme terminal.
- Python 3.11 avec Pyenv pour gérer plusieurs versions de Python sans risquer de rendre instable le macbook.
- Poetry comme gestionnaire de paquets et de dépendances pour le langage Python.
- Make, outil multiplateforme pour automatiser la compilation et l’installation de logiciels.
- Jan, un nouvel entrant apparu fin 2023, dont l’approche, 100 % Open Source, avec une licence de puristes comme je les aime et qui plus est, gratuit, pour faire tourner localement les modèles LLMs compatibles, le tout avec une interface graphique. Jan est donc notre serveur d’inférence à la place de LM Studio dans mon article précédent. Jan n’est pas un développement “from scratch” mais s’appuie sur différents composants qui sont eux-mêmes développés sous licence Open Source, dont Llama.cpp, LangChain.js, TensorRT-LLM, TheBloke/GGUF et Scalar.
Et pour l’annecdote, à propos de la philosophie que partagent les développeurs de ce projet, Jan est inspiré de la “Calm Tech” aussi appelée “Calm Design”. La “Calm Technology” ou “Calm Design” désigne une approche de conception technologique qui s’efface à l’arrière-plan, minimisant les interruptions et maximisant la tranquillité de l’utilisateur en s’intégrant harmonieusement dans son environnement quotidien. J’adore ! - HuggingFace_Hub, une librairie pour Python qui nous permettra de télécharger localement le modèle de “text embeddings” utilisé. Peut-être que dans un futur proche nous pourrons nous passer de ce composant si Jan et PrivateGPT intègrent ces fonctionnalités, let us see.
- PrivateGPT, le second gros morceau de notre POC, avec Jan, sera notre RAG local ainsi que notre interface graphique en mode web.
C’est lui qui nous fournit un cadre de développement en IA générative, privé, sécurisé, personnalisable et facile à utiliser.
Connaissances nécessaires pour ce POC
Au niveau des connaissances, pas de prérequis si ce n’est de savoir utiliser la ligne de commande dans un terminal, un éditeur comme Vim ou Nano au sein de ce terminal ou bien encore VS Code (Visual Studio Code) qui est gratuit et qui, si vous développez un peu voire beaucoup est très utile. C’est un éditeur de code source développé par Microsoft. Il est conçu pour être léger mais puissant, offrant une expérience de développement complète pour les développeurs. Notez qu’il existe des versions Libres de VS Code, tel que VSCodium .
Il vous faudra aussi quelques connaissances de Git mais là encore le strict minimum vital : savoir cloner un dépôt et je vous donne les commandes pour, si jamais pour vous c’est une découverte.
J’ajoute un petit partage linguistique au sujet d’un mot qui revient souvent en IA, c’est le mot inférence (‘inference’ en anglais). Le mot “inférence” désigne généralement le processus de tirer des conclusions ou des prédictions à partir d’informations disponibles. C’est un terme clé en logique, en statistique, en intelligence artificielle et en linguistique, parmi d’autres domaines. Dans le contexte de l’IA générative locale, sujet de nos travaux ici, l’inférence se réfère spécifiquement à l’utilisation d’un modèle pré-entraîné pour générer des résultats (comme du texte ou des images) à partir de données d’entrée. Donc ici le serveur d’inférence c’est Jan.
Entrons dans le vif du sujet !
Comme indiqué plus haut, je pars du principe que vous savez gérer les outils de base nécessaires au fonctionnement de PrivateGTP (Homebrew, Python, Pyenv, Poetry…) ou bien que vous avez consulté mon précédent article pour pouvoir les déployer.
Déploiement des composants
Pour l’installation des composants autres que Jan, si vous ne lez avez pas déjà déployer, je vous invite à vous référer à mon article précédent, ce sera la même chose ici.
Si vous avez déjà déployé LM Studio, Private_GPT, HuggingFace_Hub en suivant mon article précédent, alors je vous propose de créer une nouvelle branche de votre Git afin d’y faire vos tests pour Jan. C’est ce que je vais présenter ici :
Création d’une nouvelle branche Git pour PrivateGTP, dédiée à Jan
Placez vous dans votre répertoire /private-gpt
Vérifiez que vous êtes dans votre branche principale “main”, votre terminal doit vous afficher ceci :
private-gpt git:(main)Sinon, passez dans votre branche main avec la commande :
git checkout mainCréez une nouvelle branche adaptée à ce projet avec Jan, dans mon cas je l’ai appelée “jan-local-embeddings” pour garder la logique de mon article précédent.
git checkout -b jan-local-embeddingsVous êtes maintenant dans votre nouvelle branche fonctionnelle, votre terminal indique :
private-gpt git:(jan-local-embeddings)Profitez-en pour mettre à jour votre environnement Poetry si pas fait récemment, à la date de rédaction de cet article, je suis en version 1.8.3 :
poetry self updateInstallation de Jan
Site officiel de Jan : https://jan.ai/
Récupérez le fichier correspondant à votre système d’exploitation, dans mon cas c’est la version pour Apple Silicon (processeurs M1, M2, M3 et M4).
Notez que vous pouvez aussi installer Jan avec Homebrew, dans ce cas la commande est la suivante :
brew install --cask janAu moment où j’ai réalisé cette documentation nous en étions à la version 0.5.0 sortie début juin.
Par défaut Jan s’installe dans votre répertoire personnel : ~/jan
Si tout est bien installé vous allez déjà pouvoir jouer avec une IA générative locale sur votre mac. Vérifiez que tout fonctionne et téléchargez au moins le modèle LLM Llama 3, histoire de comparer avec le test précédent sous LM Studio. Puis sélectionnez ce modèle avant de lancer votre première conversation.
Pour vérifier que le rôle de serveur local de votre LM Studio fonctionne, après l’avoir démarré via l’icône située en bas à gauche, vous pouvez faire une requête de test pour connaître le modèle chargé. Notez qu’avec Jan, le port d’écoute par défaut est 1337.
Donc pour le test rapide, en ligne de commande, depuis votre terminal iTerm2 ou équivalent, tapez cette commande :
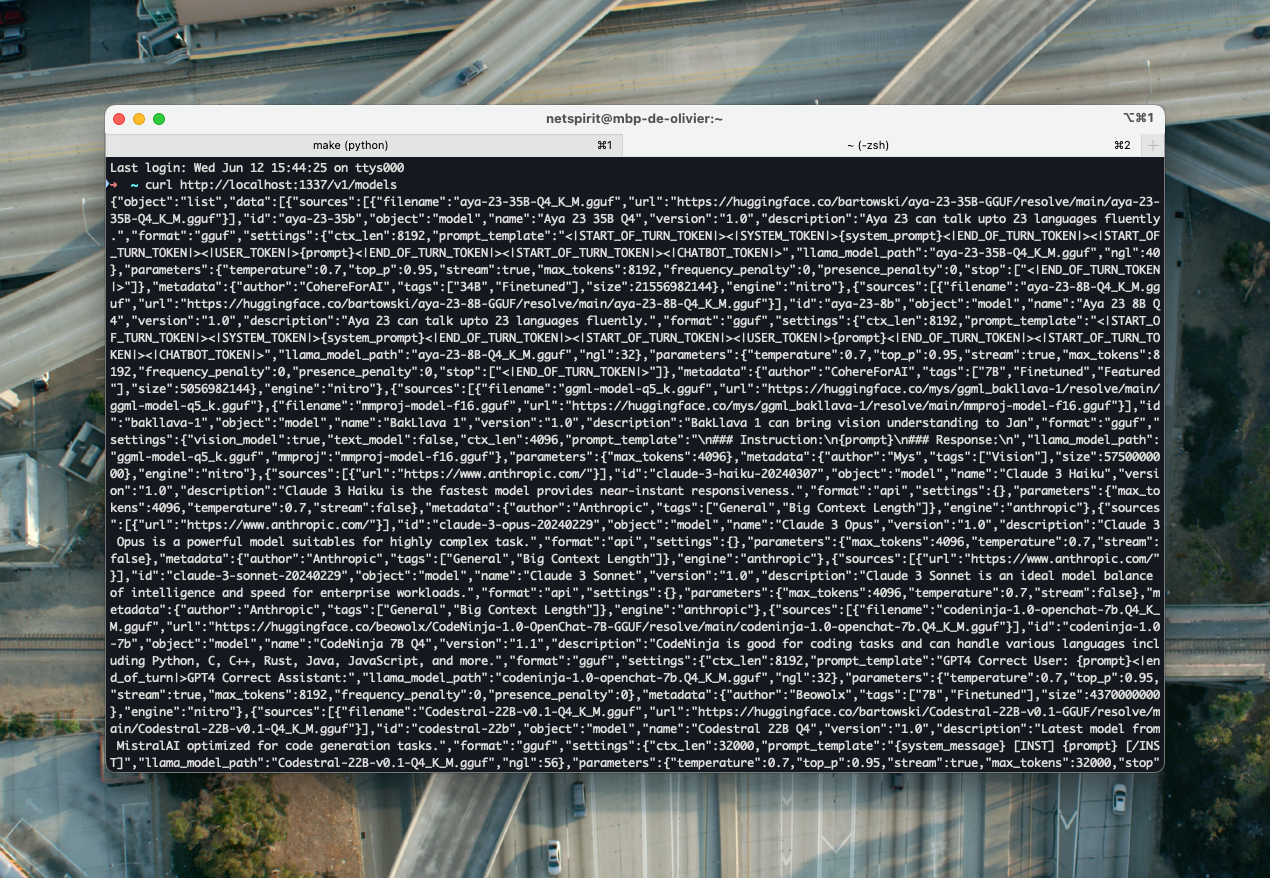
curl http://localhost:1337/v1/modelsVous devriez obtenir une réponse identique à celle-ci dans les logs du serveur Jan (pour le modèle Llama 3) :
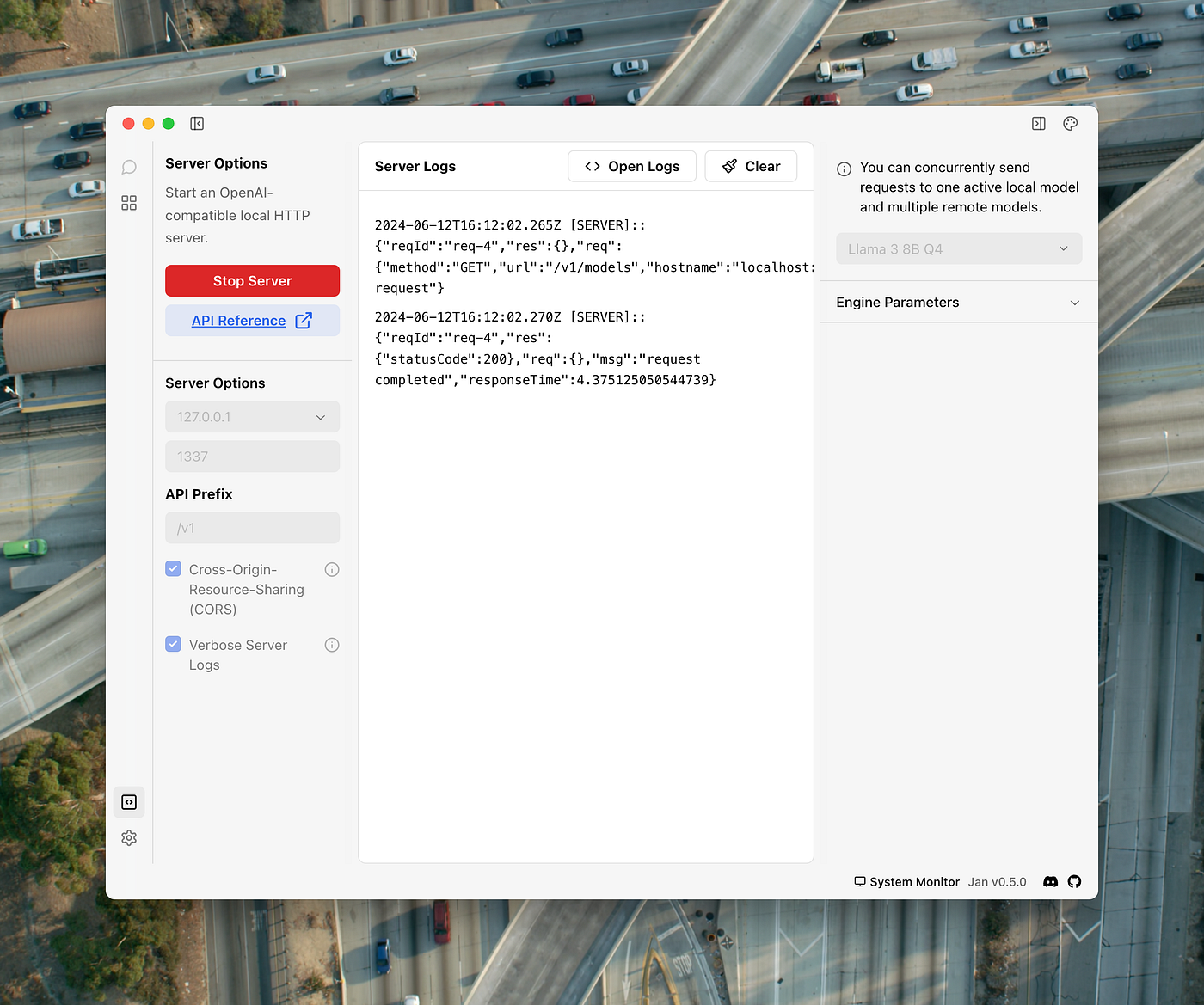
Et un message bien plus verbeux dans votre fenêtre de terminal :)
Paramétrage de PrivateGPT
Nous allons maintenant modifier le fichier de configuration adapté à notre POC, à savoir le fichier settings-vllm.yaml, que vous devez trouver à la racine de votre répertoire private-gpt.
Pourquoi celui-ci et pas un autre ? Tout simplement parce qu’il s’agit du fichier le mieux adapté, à date, pour se connecter à Jan. Tout comme pour LM Studio, il manque encore les composants permettant d’exploiter le “text embeddings” pour la vectorisation directement depuis Jan.
Pour éditer le fichier, dans votre terminal, je vous conseille l’utilisation de l’éditeur nano :
server:
env_name: ${APP_ENV:vllm}
llm:
mode: openailike
max_new_tokens: 512
tokenizer: mistralai/Mistral-7B-Instruct-v0.2
temperature: 0.1
embedding:
mode: huggingface
ingest_mode: simple
huggingface:
embedding_hf_model_name: BAAI/bge-small-en-v1.5
openai:
api_base: http://localhost:1337/v1
api_key: EMPTY
model: llama3-8b-instruct
request_timeout: 600.0Ce sont mes réglages, qui fonctionnent bien pour ce POC, à savoir pour rappel, faire une démonstration de la puissance d’une IA générative associée à un RAG pour perfectionner le modèle de LLM utilisé sur vos datas (vos fichiers à faire digérer par le RAG), le tout en local sur une machine “abordable”. Ici en utilisant des outils pleinement Open Source contrairement à LM Studio, le serveur d’inférence utilisé dans mon précédent article.
Vous pouvez bien entendu changez de modèles de LLM et de text embeddings, tester d’autres valeurs pour la température ou encore le nombre de tokens max que le LLM doit utiliser.
Démarrage de PrivateGPT
C’est le grand moment, si tout s’est bien passé jusqu’ici il n’y a pas de raison que ça ne puisse pas fonctionner, suspens…
Toujours dans votre répertoire private-gpt, en ligne de commande lancez PrivateGPT avec make, notez qu’il vous faudra maintenant toujours utiliser cette série de commande pour démarrer votre instance de PrivateGPT :
export PGPT_PROFILES=vllm
make runEt si tout est OK, vous devriez obtenir une série de lignes indiquant le bon démarrage de PrivateGPT et de son interface graphique Gradio UI disponible en localhost sur le port TCP 8001 (sans certificat SSL) :
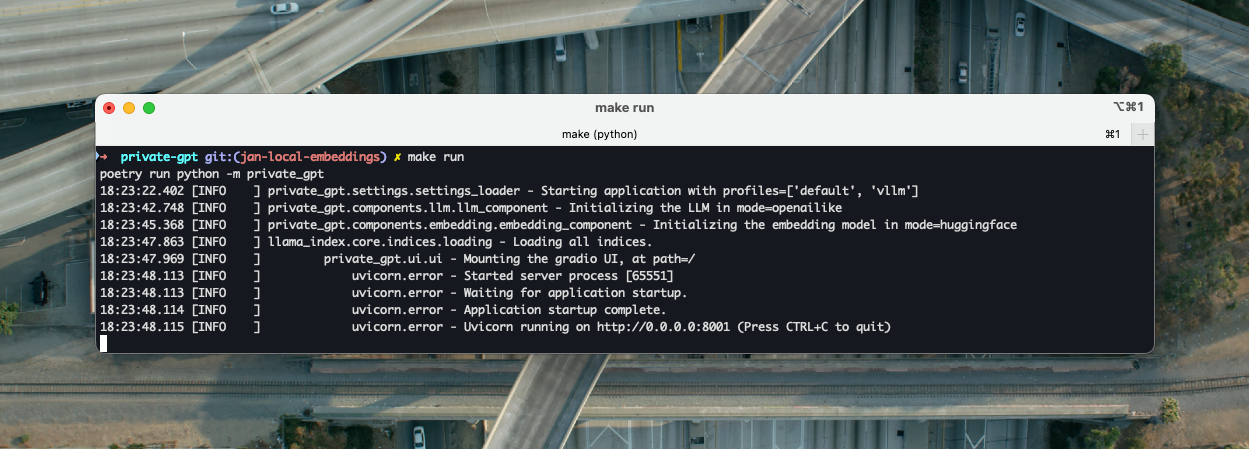
Si ça ne fonctionne pas je vous invite, encore une fois je sais, à relire et réaliser mon précédent article. Hormis LM Studio et Jan, tous les autres composants et toutes les étapes qui y sont listées sont validées sur macOS Sonoma 14.5 Sillicon (M2).
Utilisation de l’interface de PrivateGPT et test du RAG
Connectez-vous à l’aide de votre navigateur web préféré à l’adresse http://localhost:8001
Vous devriez obtenir ceci :
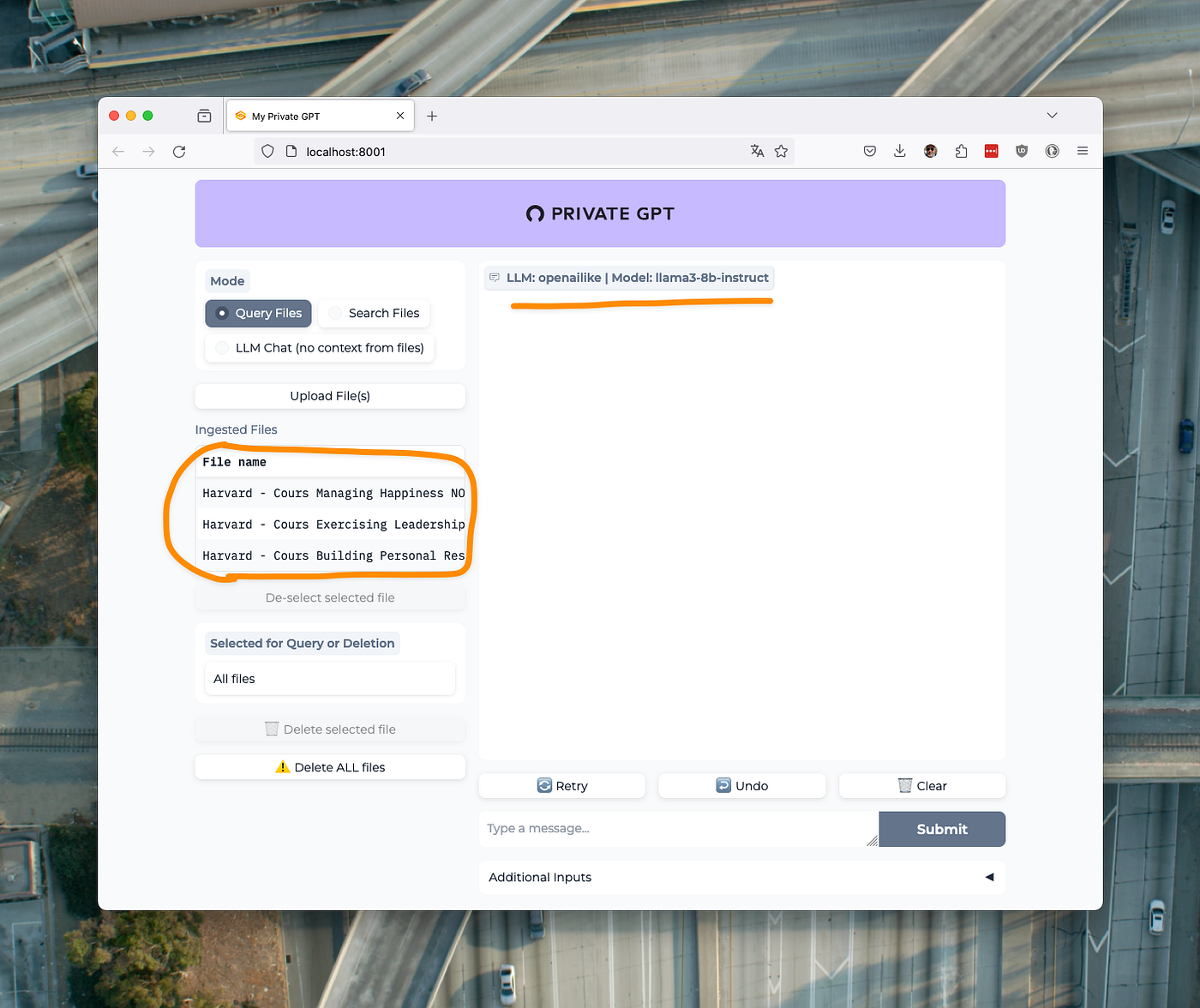
Comme j’utilise la même instance que pour mes tests précédents avec LM Studio je retrouve ici mes documents déjà ingérés par mon RAG local PrivateGPT. A savoir 3 documents PDF, des notes de cours en français, pour un total d’environ 30 000 mots.
Sur le modèle Llama 3 de META, sans aucun tunning fin, les résultats sont encore plus bluffants qu’avec mon POC précédent sous LM Studio. Cette fois je suis aussi rapide qu’un ChatGPT 4o ; sur ma machine j’obtiens une réponse finalisée en 10 secondes environ soit 6 à 7 fois plus rapide que LM Studio.
Amusez-vous à comparer des requêtes avec le contexte de vos documents (bouton Query Files activé) versus des requêtes sans le contexte (bouton LLM Chat activé).
Pour la suite
Je prévois de vous présenter prochainement une autre maquette avec Ollama (Solution en Open Source sous licence MIT), toujours sur le même dataset, pour comparer avec LM Studio et Jan.