


POC pour obtenir votre IA privée et gratuite avec Ollama et PrivateGPT
Cet article fait suite à mes deux premiers articles sur des déploiements analogues, à savoir LM Studio comme serveur d’inférence (modèle de LLM) avec sa licence très restrictive puis avec Jan dont la licence AGPL v3 est l’une des plus éthiques.
Ici nous allons créer ce POC avec Ollama qui est distribué gracieusement sous licence Open Source MIT. Toutes les infos ici : https://ollama.com/
Pas d’interface graphique mais de la ligne de commande (CLI), même si il est tout à faite possible d’installer une interface graphique, Web ou plus complète, pour Ollama, grâce aux nombreux projets qui le proposent. L’objectif ici est de rester minimaliste et de faire le job avec le moins de composants possibles.
Je pars du principe que vous avez suivi mon premier article, à minima pour les explications théoriques et les outils de base nécessaires à la construction de ce POC (Proof of Concept). Sinon je vous invite grandement à le faire si vous n’avez pas déjà les compétences requises dans ce domaine !
Technologies nécessaires pour ce POC
- Plateforme Apple macbook Pro M2 MAX avec 32 Go de mémoire vive.
- Homebrew comme gestionnaire de paquets pour le système d’exploitation macOS.
- iTerm2 comme terminal.
- Python 3.11 avec Pyenv pour gérer plusieurs versions de Python sans risquer de rendre instable le macbook.
- Poetry comme gestionnaire de paquets et de dépendances pour le langage Python.
- Make, outil multiplateforme pour automatiser la compilation et l’installation de logiciels.
- Ollama, un framework codé en Go (à 83 %) pour faire tourner localement des modèles de LLM. Ici on est sous licence MIT, donc en Open Source mais avec beaucoup de liberté, y-compris celle d’intégrer le code dans du code propriétaire. Donc on aime pour la simplicité et l’encouragement à l’innovation que fournit cette licence, on aime moins pour le risque de se faire piller son code par des pilleurs de tombes, oups, de dépôt Git and co.
- PrivateGPT, le second gros morceau de notre POC, avec Ollama, sera notre RAG local ainsi que notre interface graphique en mode web.
C’est lui qui nous fournit un cadre de développement en IA générative, privé, sécurisé, personnalisable et facile à utiliser.
Connaissances nécessaires pour ce POC
Au niveau des connaissances, pas de prérequis si ce n’est de savoir utiliser la ligne de commande dans un terminal, un éditeur comme Vim ou Nano au sein de ce terminal ou bien encore VS Code (Visual Studio Code) qui est gratuit et qui, si vous développez un peu voire beaucoup est très utile. C’est un éditeur de code source développé par Microsoft. Il est conçu pour être léger mais puissant, offrant une expérience de développement complète pour les développeurs. Ah oui, quelques connaissances de Git mais là encore le strict minimum vital : savoir cloner un dépôt et je vous donne les commandes si c’est pour vous une découverte.
C’est parti !
Comme indiqué plus haut, je pars du principe que vous savez gérer les outils de base nécessaires au fonctionnement de PrivateGPT (Homebrew, Python, Pyenv, Poetry…) ou bien que vous avez consulté mon premier article pour pouvoir les déployer.
Déploiement des composants
Si vous avez déjà déployé LM Studio ou Jan, PrivateGPT, HuggingFace_Hub en suivant mes articles précédents, alors je vous propose de créer une nouvelle branche de votre Git afin d’y faire vos tests pour Ollama. C’est ce que je vais présenter ici :
Création d’une nouvelle branche Git pour PrivateGTP, dédiée à Ollama
Placez vous dans votre répertoire de développement /private-gpt
Vérifiez que vous êtes dans votre branche principale “main”, votre terminal doit vous afficher ceci :
private-gpt git:(main)Sinon, passez dans votre branche main avec la commande :
git checkout mainCréez une nouvelle branche adaptée à ce projet avec le framework Ollama, dans mon cas je l’ai appelée “ollama-local-embeddings” pour garder la logique de mes deux articles précédents.
git checkout -b ollama-local-embeddingsVous êtes maintenant dans votre nouvelle branche fonctionnelle, votre terminal indique :
private-gpt git:(ollama-local-embeddings)Profitez-en pour mettre à jour votre environnement Poetry si pas fait récemment, à la date de rédaction de cet article, je suis en version 1.8.3 :
poetry self updateInstallation de Ollama sous macOS
Site officiel de Ollama : https://ollama.com
Téléchargez l’archive pour macOS.
Dézippez-la puis installez l’application Ollama dans vos applications.
Notez que vous pouvez aussi installer Ollama avec Homebrew, dans ce cas la commande est la suivante :
brew install --cask ollamaAu moment où j’ai réalisé cette documentation nous en sommes à la version 0.1.46 d’Ollama sortie le 20 juin sur son dépôt Github : https://github.com/ollama/ollama
Si tout est bien installé et tout comme avec LM Studio ou Jan de mes articles précédents, vous allez déjà pouvoir jouer avec une IA générative locale sur votre mac.
Premiers pas avec Ollama et commandes essentielles :
Nous allons vérifier que tout fonctionne et télécharger au moins le modèle LLM “Llama 3”, histoire de comparer avec ce que nous avons déjà réalisé ensemble.
Tout ce qui suit se passe dans votre terminal préféré, dans mon cas j’utilise iTerm2.
Vérifier la version installée :
ollama --version Vous devriez obtenir quelque chose comme :
ollama version is 0.1.46Pour lister vos modèles de LLM déjà téléchargés ou créés dans Ollama :
ollama listSi vous venez d’installer Ollama et que vous n’avez rien chargé, votre liste sera vide.
Télécharger un modèle LLM, dans notre cas nous choisissons le modèle Llama3 :
ollama pull llama3Lancer un modèle LLM :
ollama run llama3 Notez que si vous ne l’aviez pas déjà téléchargé il le sera en premier lieu puis démarrera, et en fonction de votre bande passante, le téléchargement peut prendre beaucoup de temps !
Après quelques secondes liées au démarrage de votre instance Ollama avec le modèle LLM chargé, vous obtiendrez une invite de prompt semblable à celle-ci :
>>> Send a message (/? for help)Vous pouvez tester !
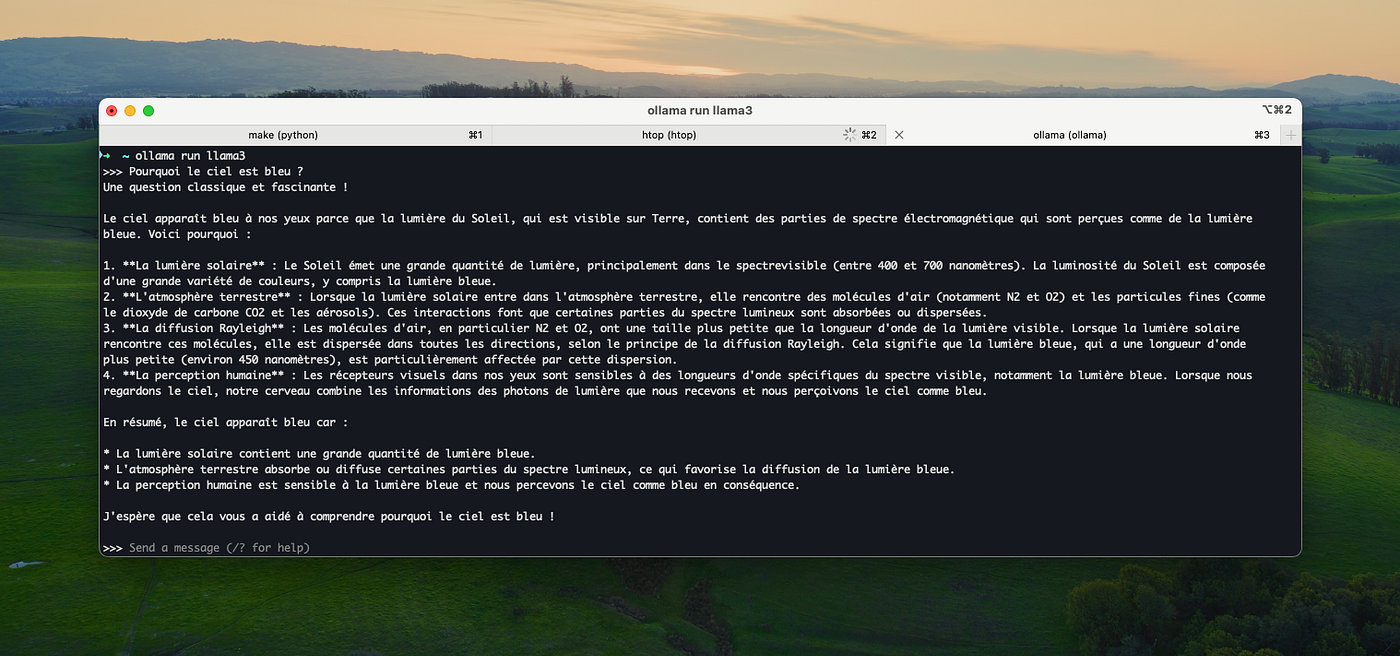
Pour effacer un modèle et faire de la place :
ollama rm modelnamePour les infos de base, c’est simple :
/?Pour switcher entre vos modèles :
ollama run mistralEt pour quitter l’invite de commande :
/byeDémarrons maintenant le serveur d’Ollama :
Vous pouvez démarrer Ollama avec la commande suivante :
ollama serveSi tout comme moi vous l’avez installé depuis l’archive disponible sur le site votre instance d’Ollama est sans doute déjà en service et vous obtiendrez le message suivant :
Error: listen tcp 127.0.0.1:11434: bind: address already in useTestons facilement si le serveur fonctionne, pour cela ouvrez un navigateur web tapez -y ceci :
Vous devriez obtenir un “Ollama is running” en haut et à gauche de votre fenêtre de navigation comme ceci :

Installation des dépendances pour le fonctionnement de PrivateGPT avec Ollama :
Installons maintenant les dépendances Poetry nécessaires au bon fonctionnement de PrivateGPT avec Ollama. Notez que la commande suivante supprimera les dépendances de nos POCs précédents avec LM Studio et Jan. Si vous souhaitez conserver les trois instances opérationnelles alors adaptez votre commande en y incluant l’ensemble des dépendances.
poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"Vous devriez voir dans votre terminal se dérouler l’installation de tous les packages nécessaires au projet.
Quelques explications utiles sur les arguments, situés entre les double-quotes (guillemets), de cette ligne de commande :
uipour utiliser l’UI Gradiollms-ollamapour se connecter à Ollama qui est, rappelons-le si besoin, un LLM local Open Source sous licence MIT.embeddings-ollamapour pouvoir utiliser localement donc, dans Ollama, un modèle d’ingestion pour la vectorisation de nos documents. Ces modèles servent à convertir des mots, des phrases ou des documents entiers en vecteurs de nombres. Ces vecteurs captent des aspects sémantiques du texte, ce qui permet aux algorithmes de travailler avec du texte en utilisant des opérations mathématiques. J’essaierai de vous faire un article ultérieurement sur ce que sont les vecteurs.vector-stores-qdrantpour le stockage des fameux vecteurs créés au format Qdrant.
Paramétrage de PrivateGPT
Nous allons maintenant modifier le fichier de configuration adapté à notre POC, à savoir le fichier settings-ollama.yaml, que vous devriez trouver à la racine de votre répertoire private-gpt.
Pour éditer le fichier, dans votre terminal, je vous conseille l’utilisation de l’éditeur nano :
nano settings-ollama.yamlserver:
env_name: ${APP_ENV:ollama}
llm:
mode: ollama
max_new_tokens: 512
context_window: 3900
temperature: 0.1 #The temperature of the model. Increasing the temperature will make the model answer more creatively. A value of 0.1 would be more factual. (Default: 0.1)
embedding:
mode: ollama
ollama:
llm_model: llama3
embedding_model: nomic-embed-text
api_base: http://localhost:11434
embedding_api_base: http://localhost:11434 # change if your embedding model runs on another ollama
keep_alive: 5m
tfs_z: 1.0 # Tail free sampling is used to reduce the impact of less probable tokens from the output. A higher value (e.g., 2.0) will reduce the impact more, while a value of 1.0 disables this setting.
top_k: 40 # Reduces the probability of generating nonsense. A higher value (e.g. 100) will give more diverse answers, while a lower value (e.g. 10) will be more conservative. (Default: 40)
top_p: 0.9 # Works together with top-k. A higher value (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text. (Default: 0.9)
repeat_last_n: 64 # Sets how far back for the model to look back to prevent repetition. (Default: 64, 0 = disabled, -1 = num_ctx)
repeat_penalty: 1.2 # Sets how strongly to penalize repetitions. A higher value (e.g., 1.5) will penalize repetitions more strongly, while a lower value (e.g., 0.9) will be more lenient. (Default: 1.1)
request_timeout: 120.0 # Time elapsed until ollama times out the request. Default is 120s. Format is float.
vectorstore:
database: qdrant
qdrant:
path: local_data/private_gpt/qdrantVous remarquerez au passage que dans ce test je n’utilise plus le modèle d’embedding BAAI/bge-small-en-v1.5 que j’ai utilisé dans mes deux précédents tests mais plutôt le modèle nomic-embed-text. La raison est très simple, Ollama fournit un moteur d’ingestion utilisable par PrivateGPT, ce que ne proposait pas encore PrivateGPT pour LM Studio et Jan mais le modèle BAAI/bge-small-en-v1.5 n’est pas disponible chez Ollama.
Nous verrons dans nos tests si cela change la qualité des réponses fournies.
Vous pouvez bien entendu changez de modèles de LLM et de text embeddings, tester d’autres valeurs pour la température ou encore le nombre de tokens max que le LLM doit utiliser.
Chargement du modèle d’embedding dans Ollama :
Plus haut nous avons téléchargé le modèle de LLM Llama3 mais vu que Ollama va aussi nous servir pour le rôle d’ingestion afin de digérer nos documents et de les vectoriser avec PrivateGPT, il nous faut télécharger le modèle que nous avons déclaré dans la configuration de ce dernier, à savoir : nomic-embed-text, avec la commande qui va bien :
ollama pull nomic-embed-textSi vous listez maintenant vos modèles vous devriez avoir à minima ceci :

Pour vider la base Qdrant utilisez cette commande dans PrivateGPT :
make wipeQui devrait vous retourner un résultat équivalent à celui-ci :
private-gpt git:(ollama-local-embeddings) ✗ make wipe
poetry run python scripts/utils.py wipe
17:46:59.739 [INFO ] private_gpt.settings.settings_loader — Starting application with profiles=[‘default’, ‘ollama’]
— Deleted /Users/netspirit/DEV/private-gpt/local_data/private_gpt/docstore.json
— Deleted /Users/netspirit/DEV/private-gpt/local_data/private_gpt/index_store.json
Collection dropped successfully.Démarrage de PrivateGPT
C’est le grand moment, si tout s’est bien passé jusqu’ici il n’y a pas de raison que ça ne puisse pas fonctionner, suspens…
Toujours dans votre répertoire private-gpt, en ligne de commande, lancez PrivateGPT avec make, notez qu’il vous faudra maintenant toujours utiliser cette série de commande pour démarrer votre instance de PrivateGPT :
export PGPT_PROFILES=ollama
make runVous pouvez tester que le modèle ollama est bien chargé pour votre PrivateGPT avec la commande :
echo $PGPT_PROFILESQui doit vous retourner :
ollamaUtilisation de l’interface de PrivateGPT et test du RAG
Connectez-vous à l’aide de votre navigateur web préféré à l’adresse http://localhost:8001
Vous devriez obtenir ceci :
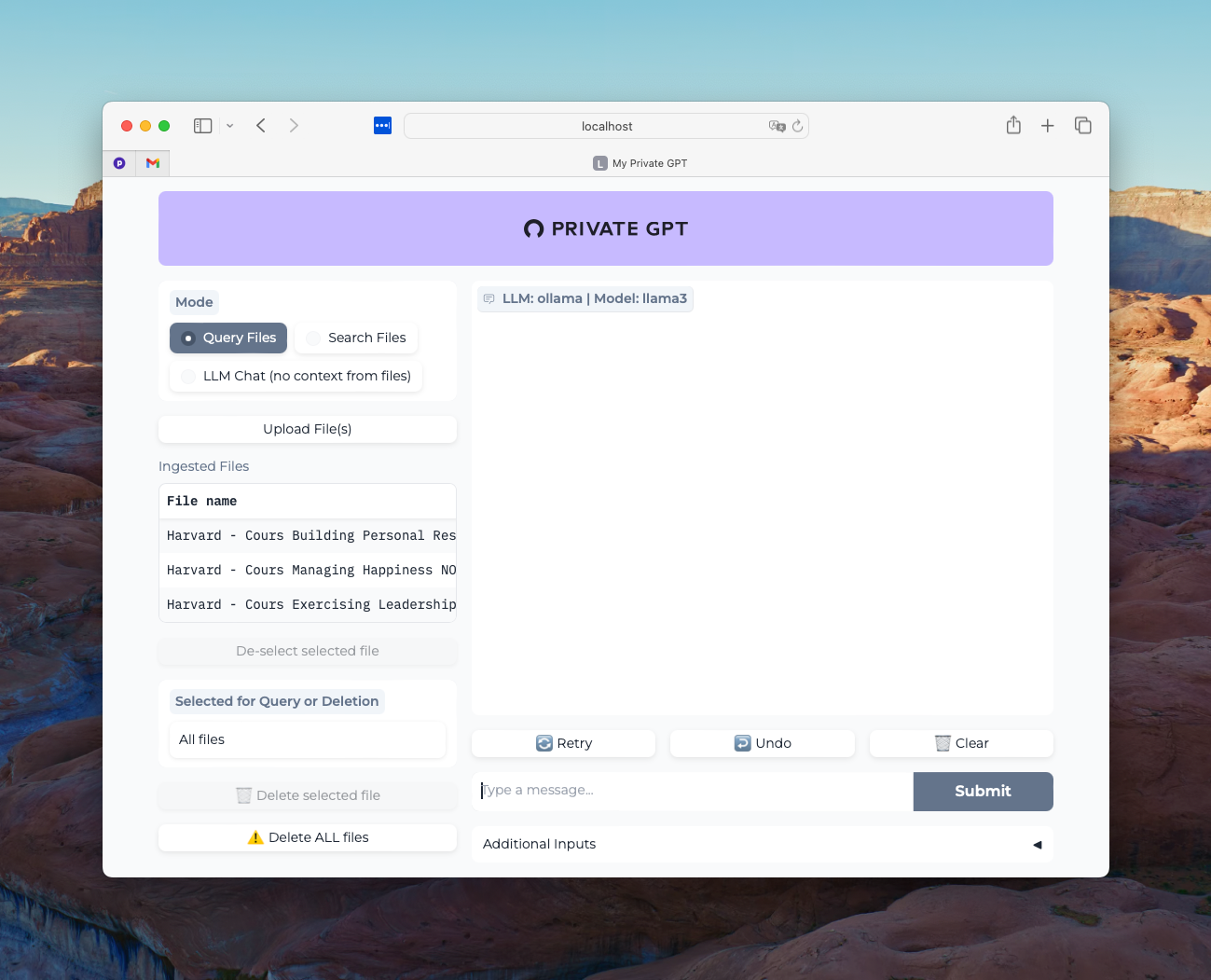
A ceci près que vous ne devriez pas avoir de fichiers présents dans la colonne “Ingested Files”. Si vous retrouvez ici vos fichiers des tests précédents je vous invite à les supprimer puis à relancer la commande de suppression du contenu de votre base vectorielle Qdrant :
make wipePour mes tests, j’ai chargé dans le RAG des notes de mes cours dédiés au leadership et à l’amélioration de la santé mentale, 3 documents PDF pour un total d’environ 30 000 mots, tout comme je l’avais fait pour LM Studio et Jan.
Si en chargeant vos propres fichiers vous obtenez une erreur identique à :
ValueError: could not broadcast input array from shape (768,) into shape (384,)
Alors relisez l’AVIS IMPORTANT au chapitre “Chargement du modèle d’embedding dans Ollama” :-)
Sur le modèle Llama 3 de META, sans aucun tunning fin, les résultats sont encore plus bluffants qu’avec mes POC précédents sous LM Studio puis sous Jan. Je suis toujours aussi rapide qu’un ChatGPT 4o.
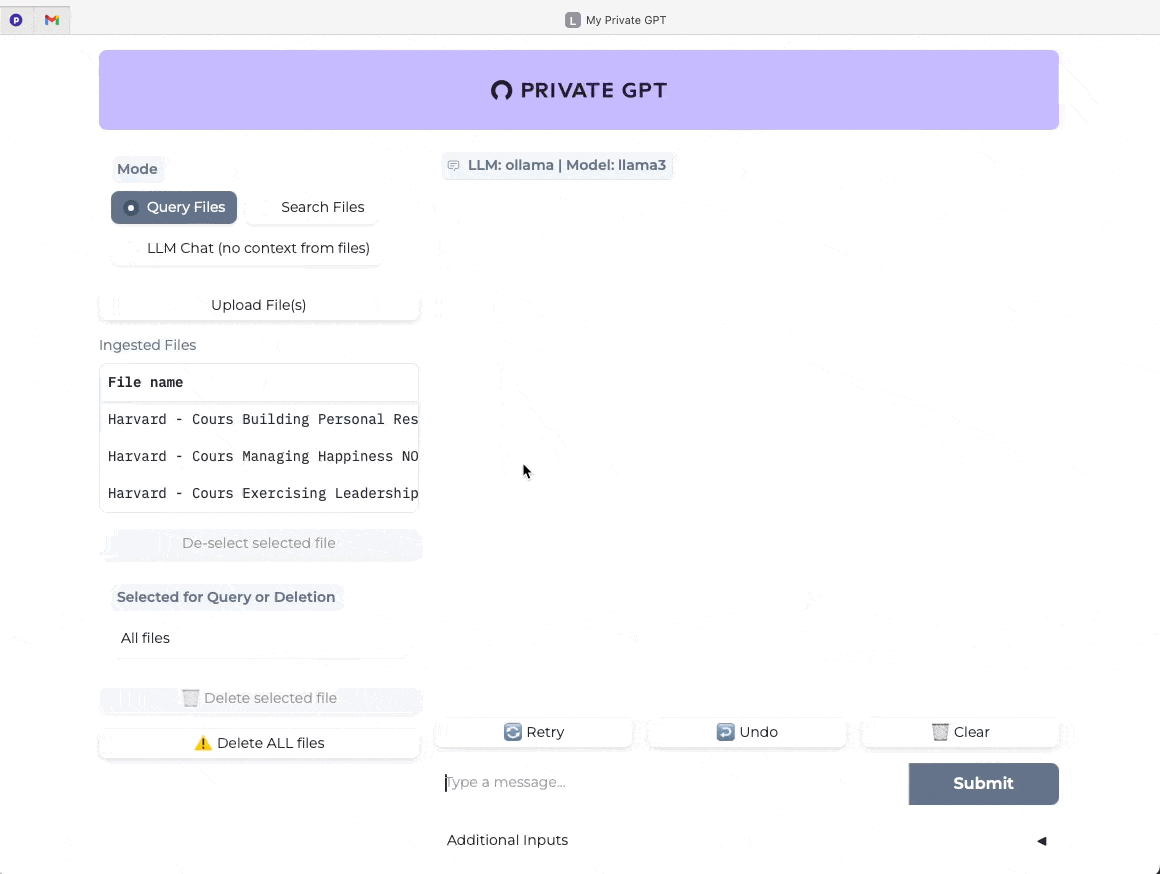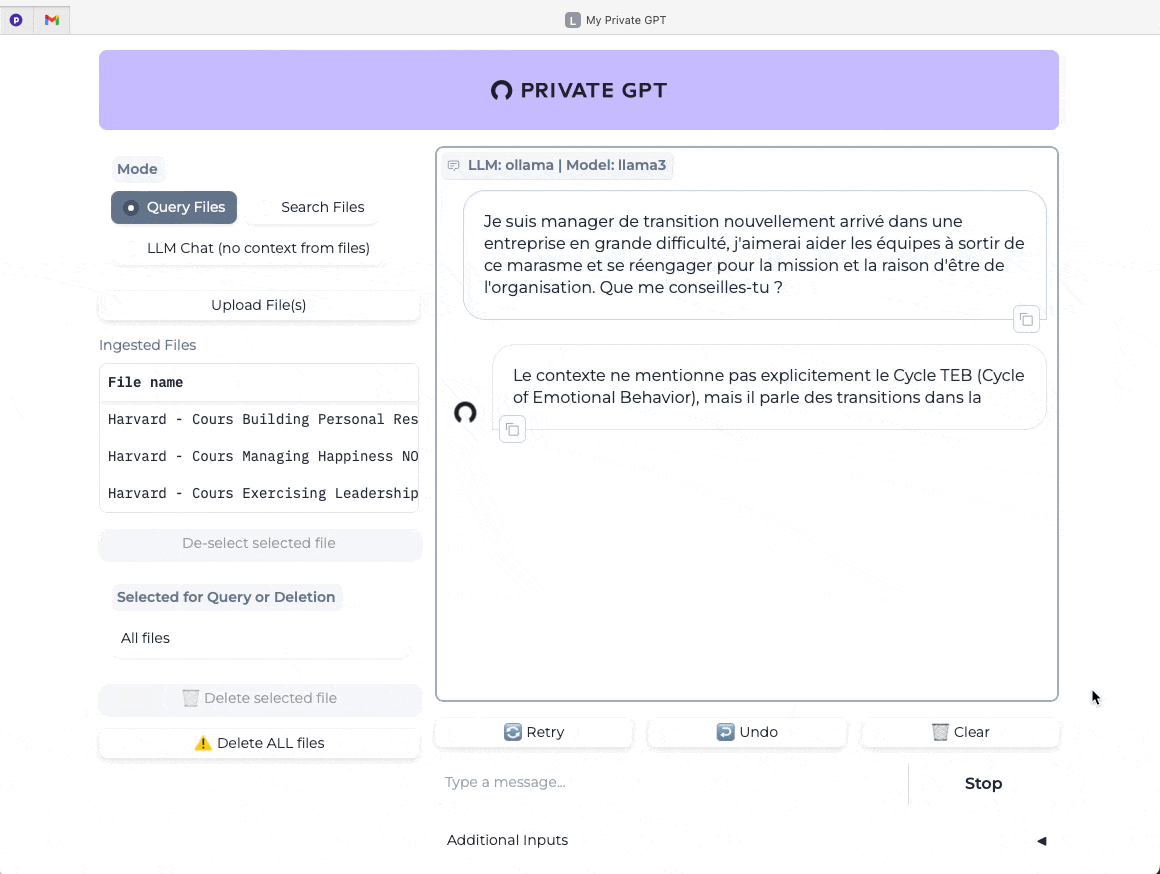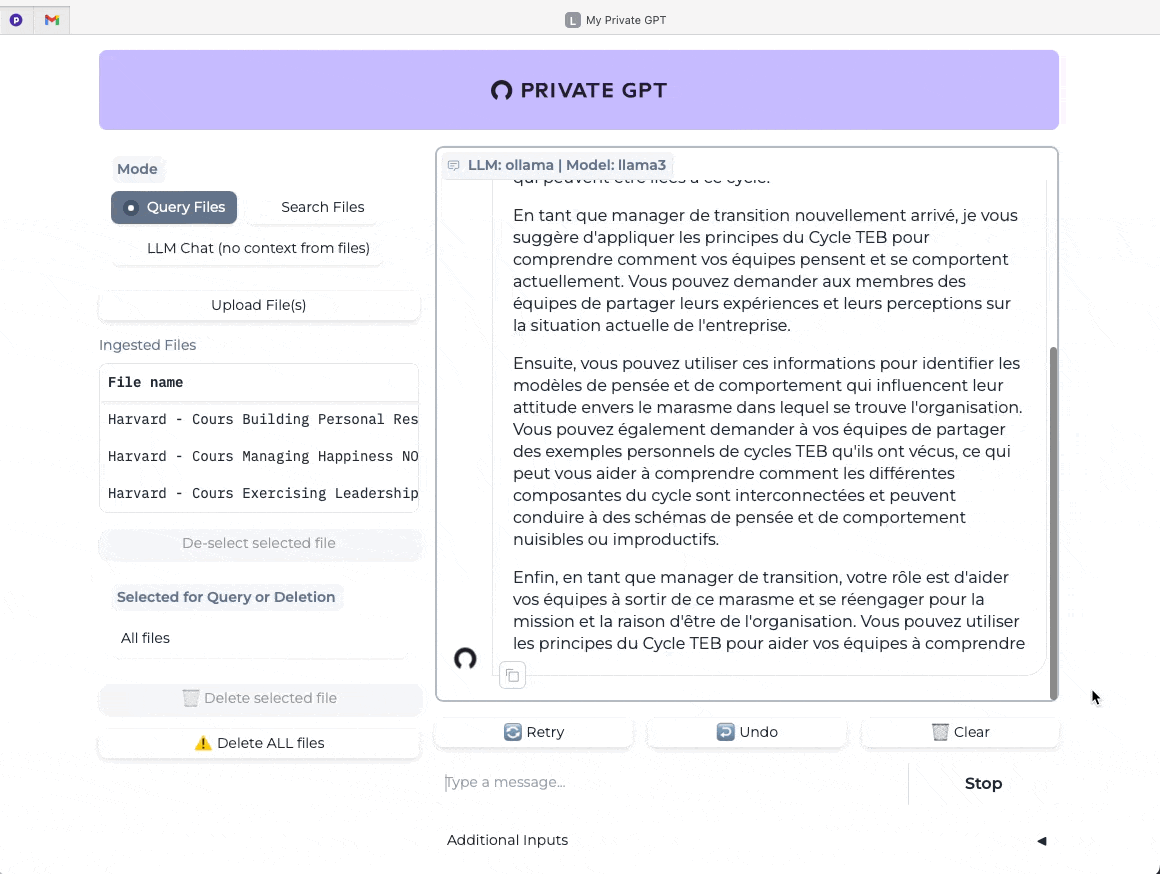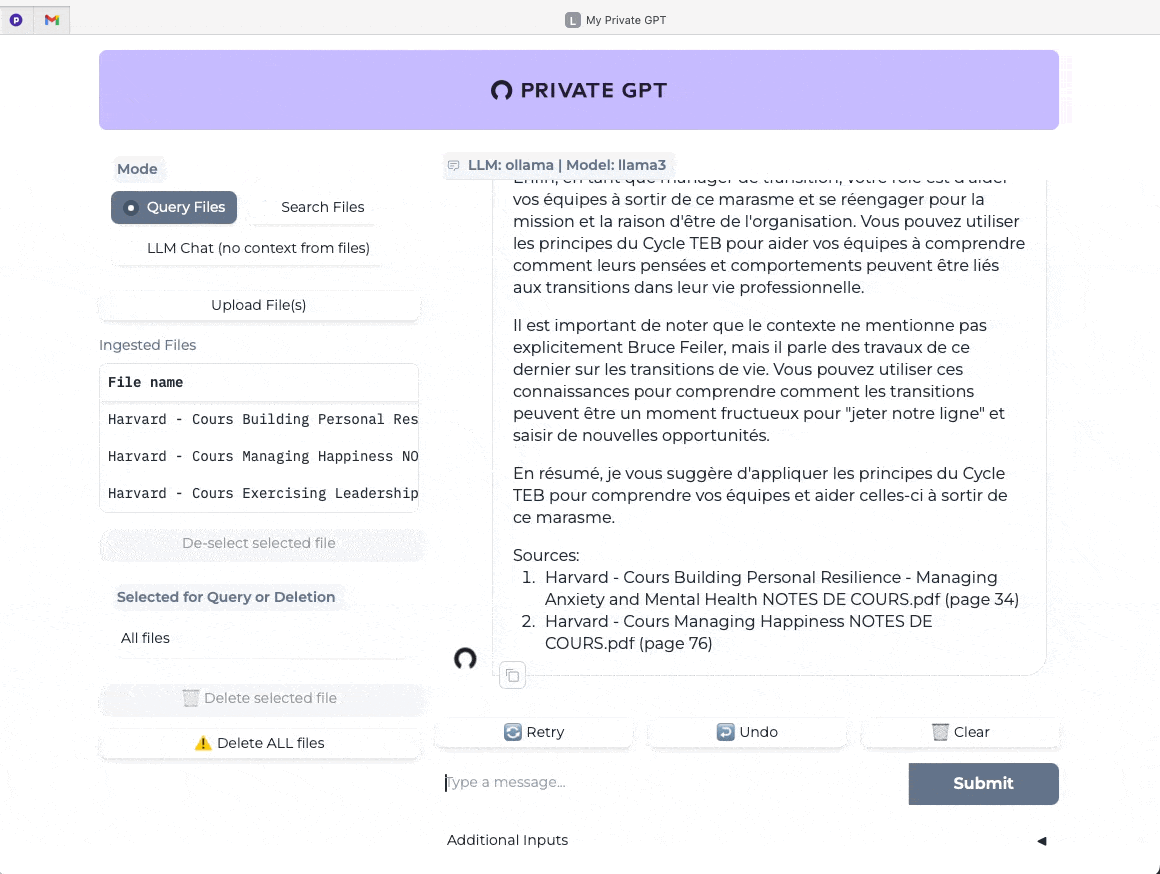
Amusez-vous à comparer des requêtes avec le contexte de vos documents (bouton Query Files activé) versus des requêtes sans le contexte (bouton LLM Chat activé).
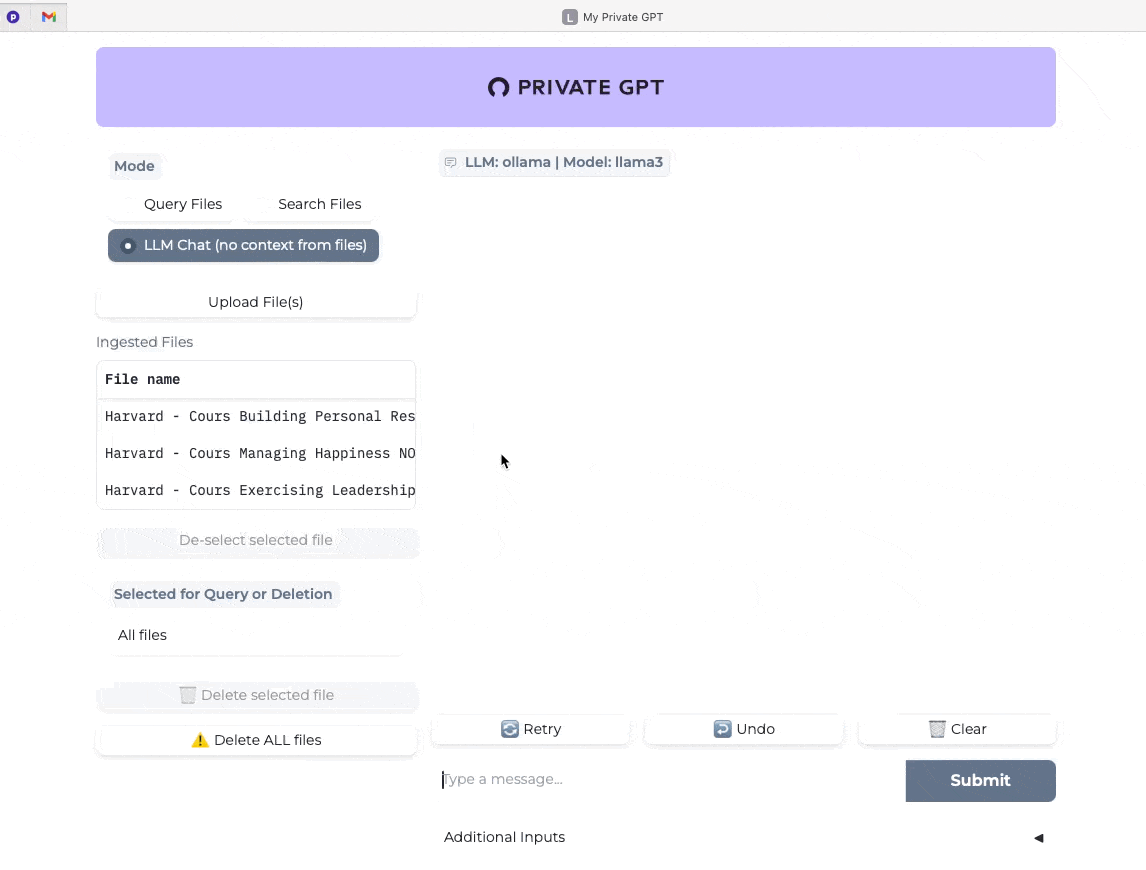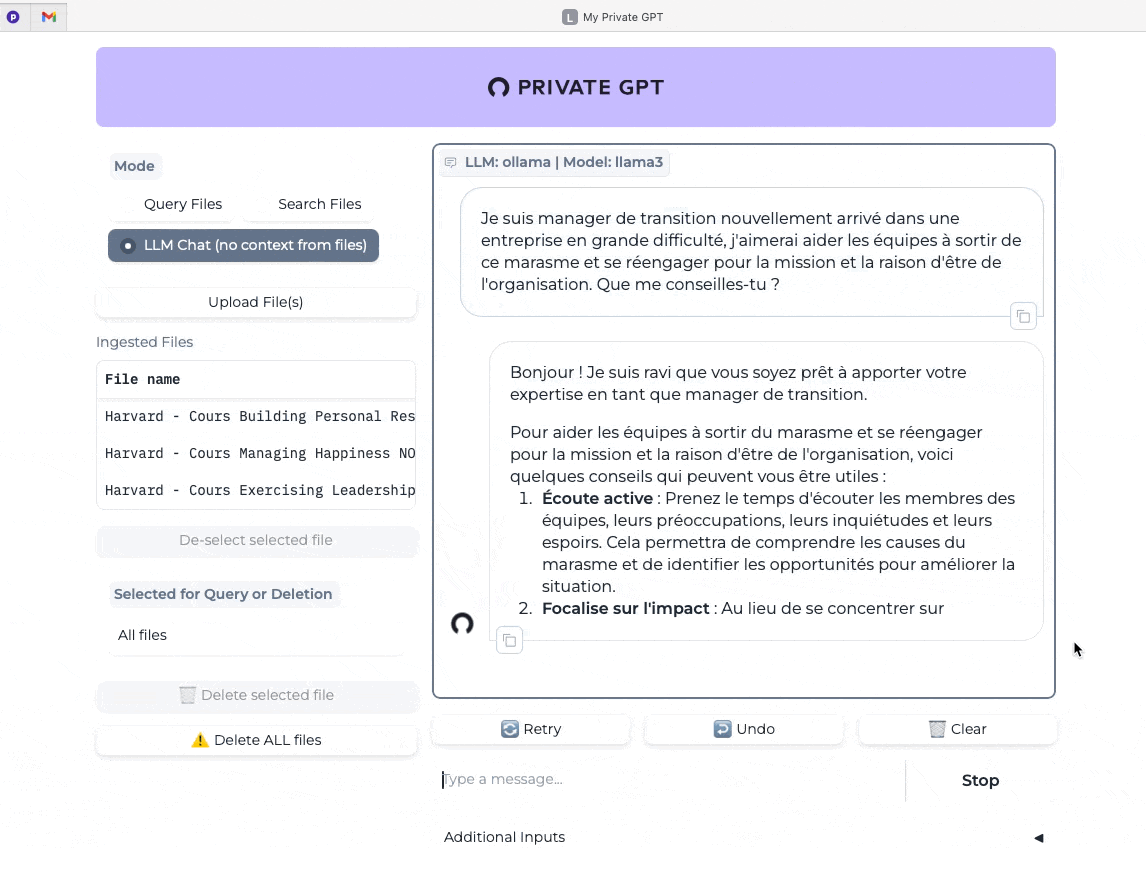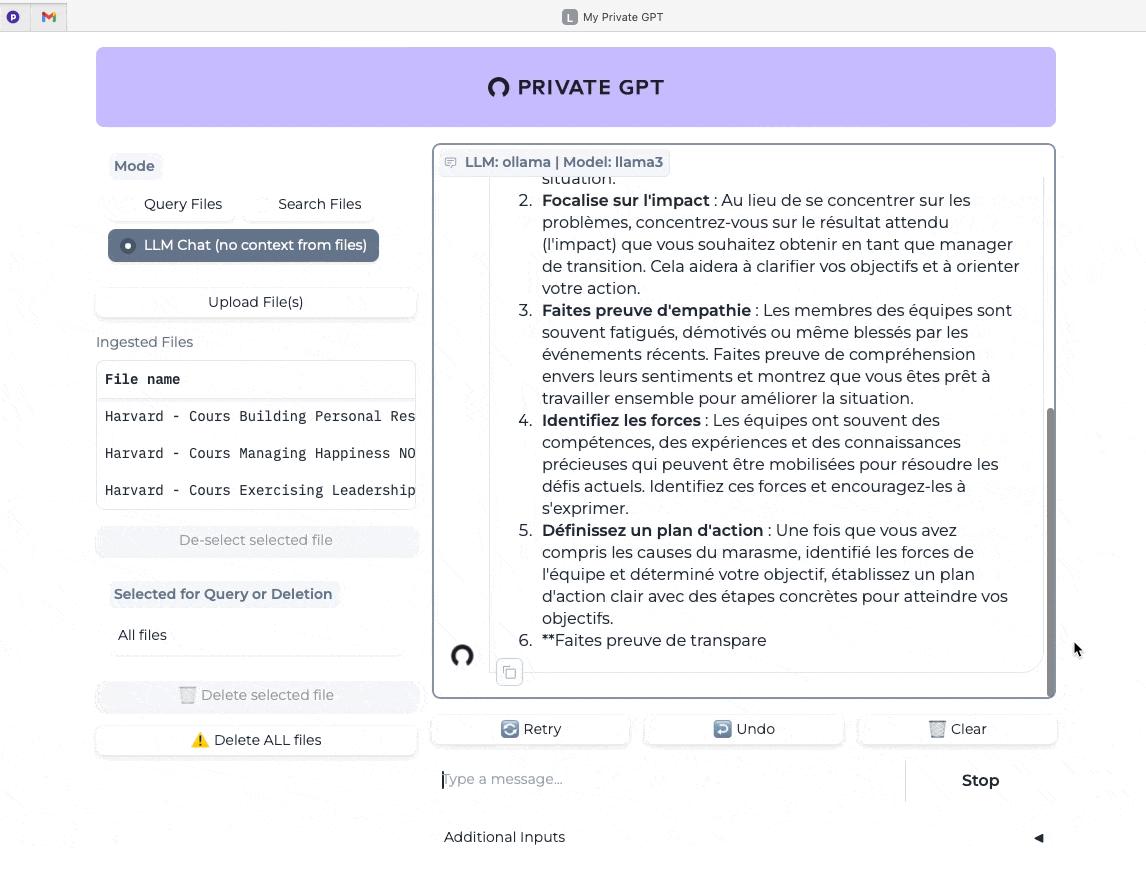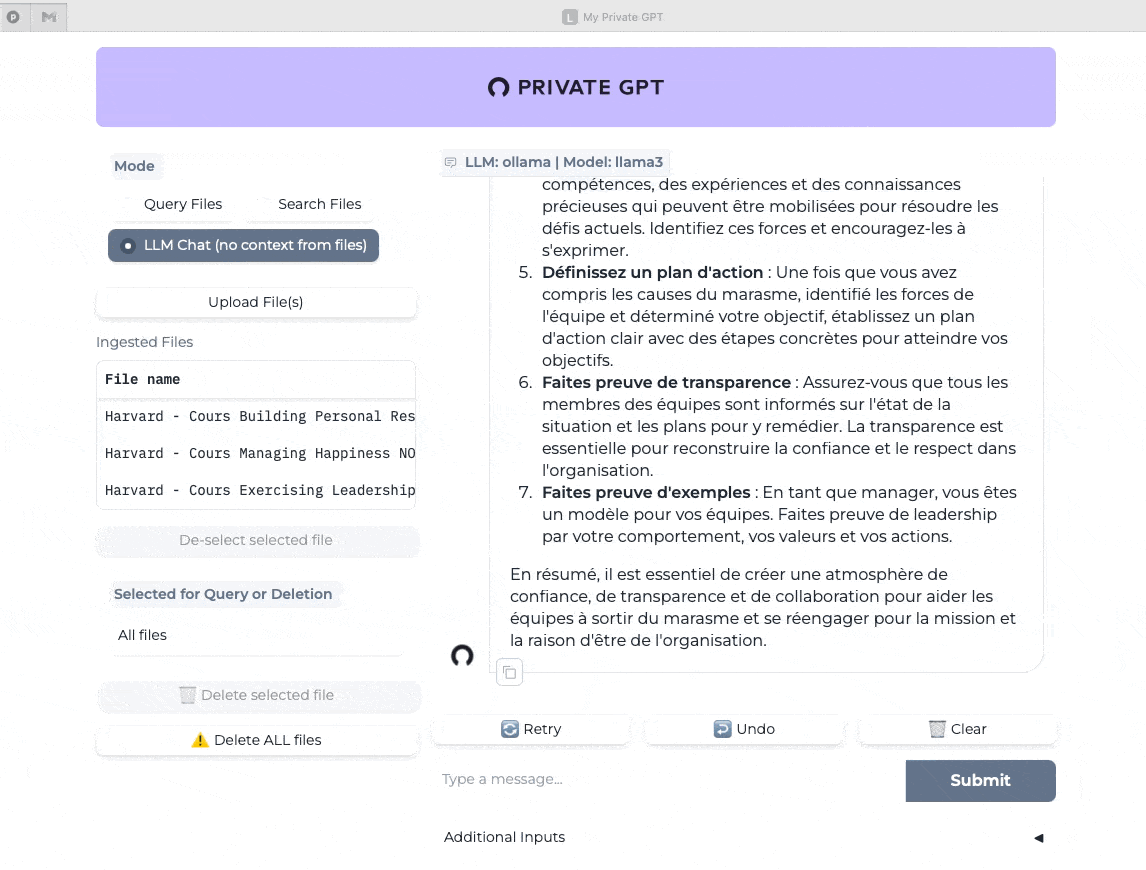
Dans l’exemple qui suit, après avoir effacé l’historique, j’ai utilisé la même requête mais sans le contexte apporté par mes notes de cours.
Dernier test avec cette fois le mode “recherche dans les fichiers” (Search Files) et je pose la même question. On mesure ici la vitesse quasi instantanée de la réponse et sa pertinence (j’ai validé dans mes notes de cours).
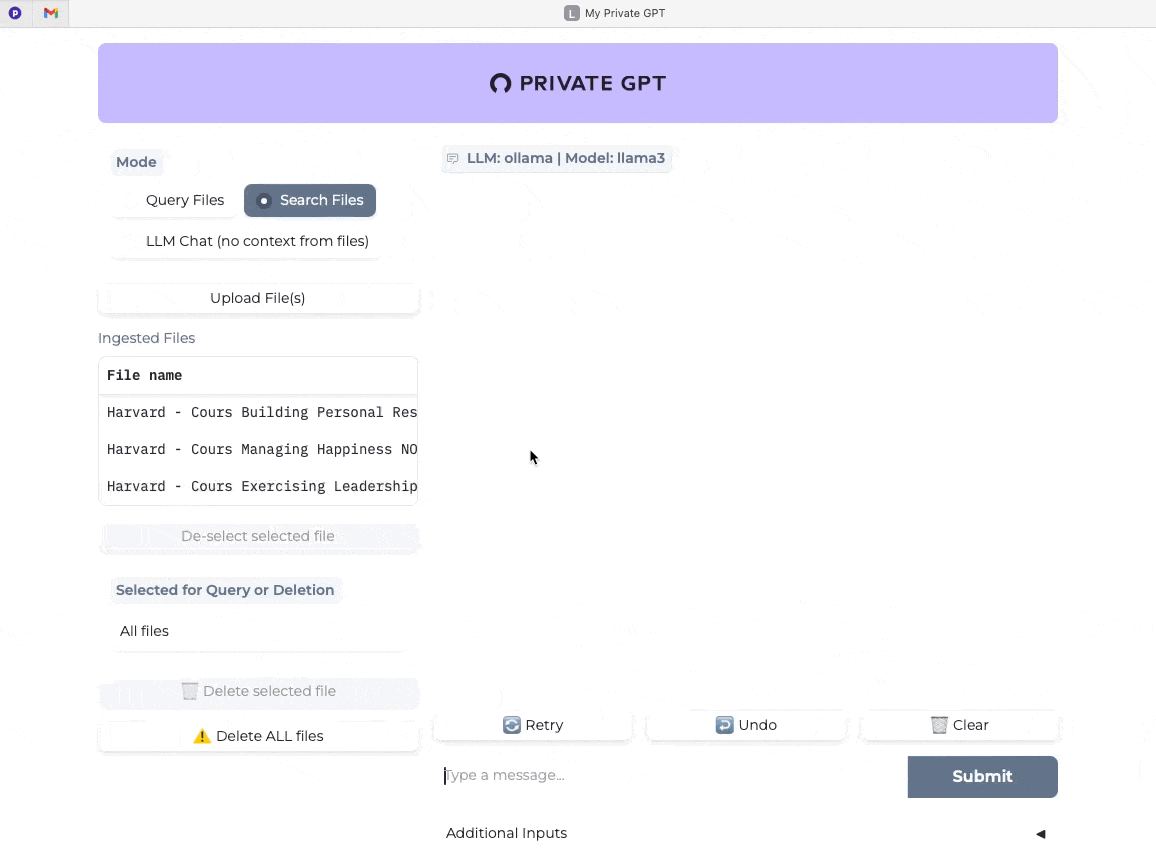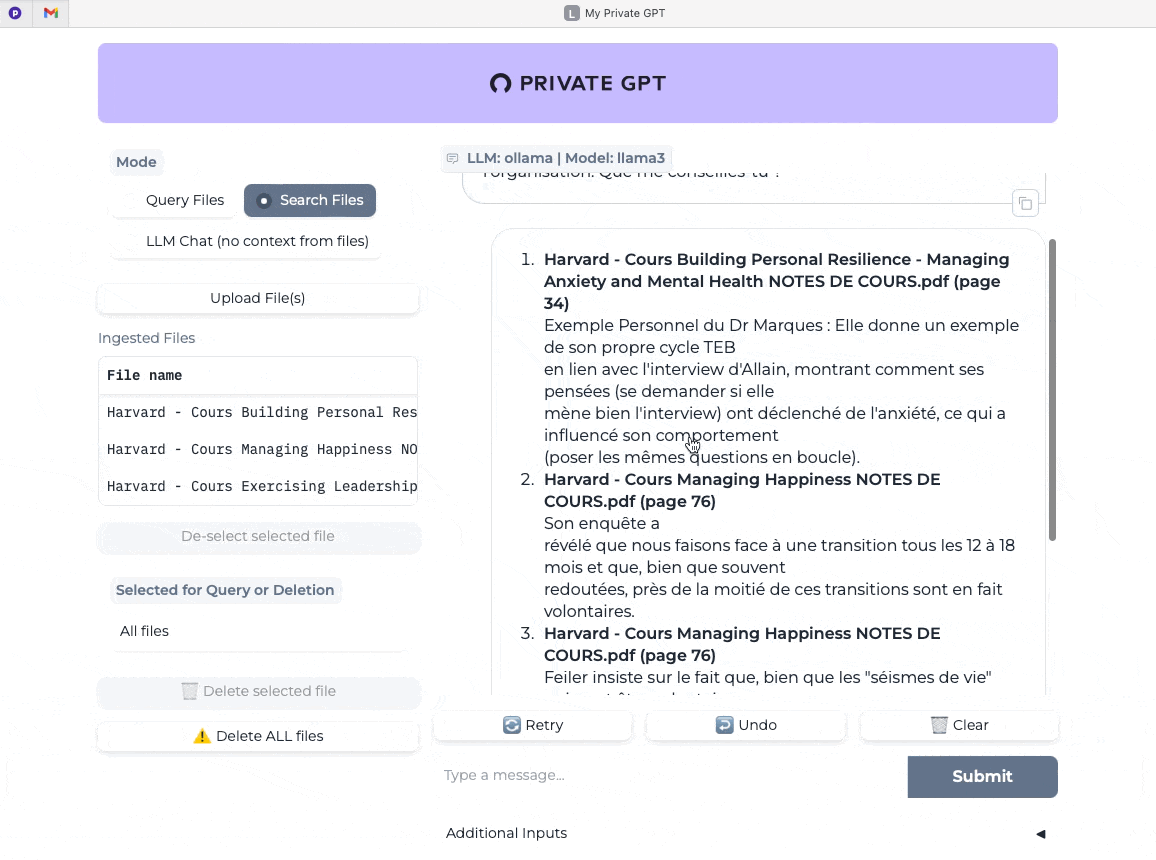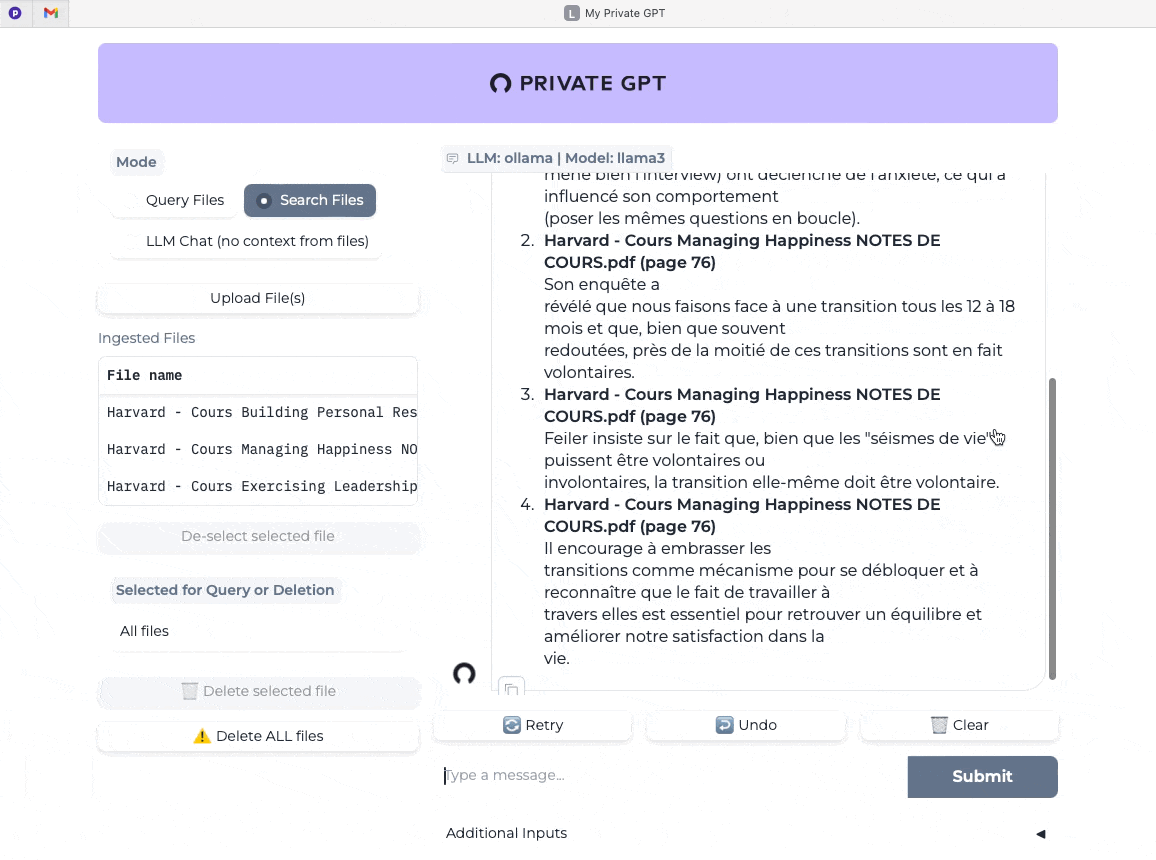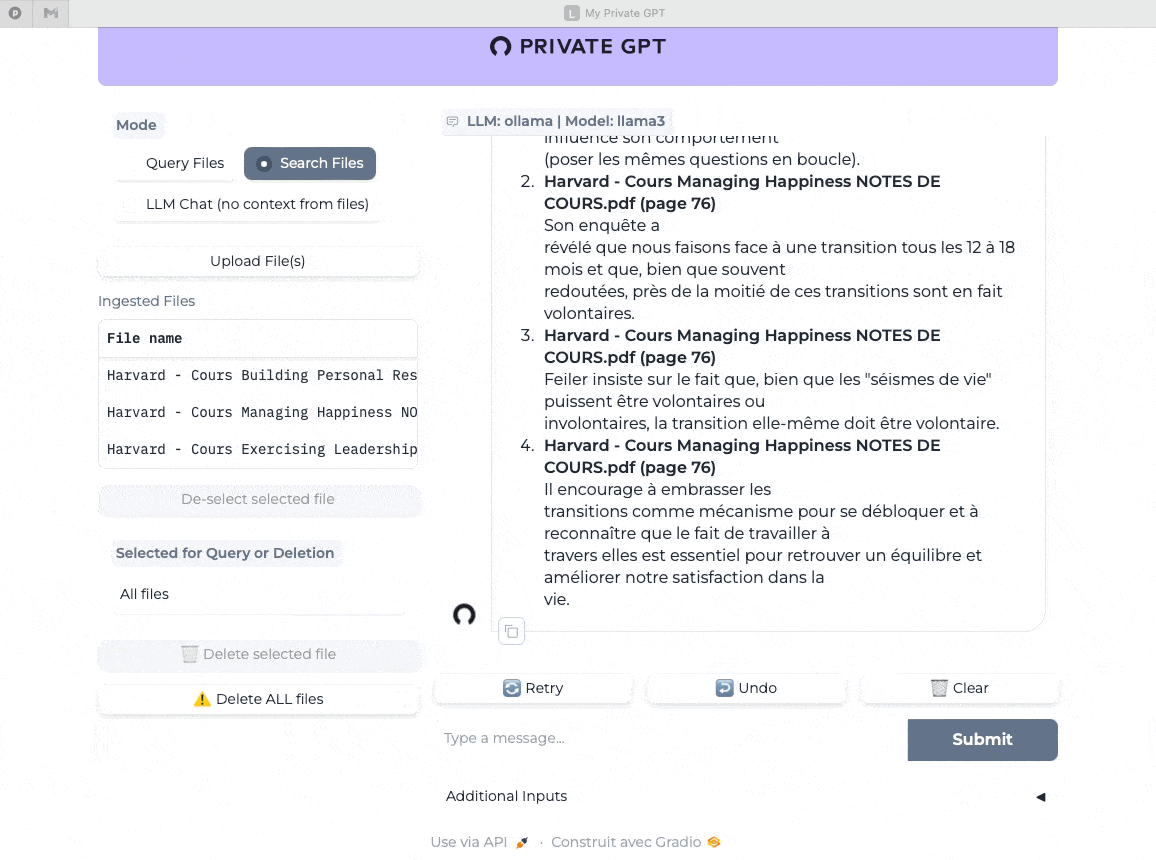
Bien évidemment et tout comme pour LM Studio et Jan, ou encore ChatGPT, Claude, Gemini et les autres, le plus important après les briques techniques, c’est vous et votre capacité à challenger l’IA mais ça c’est un autre sujet ;-)
Pour la suite
Un peu de buzz…
Il s’avère que je travaille depuis plusieurs mois avec trois compères sur la mise au point d’une solution d’IA locale, privée, hautement sécurisée, minimaliste et Open Source (licence MIT à minima) pour les organisations qui souhaitent mieux exploiter leurs datas tout en restant souveraines au sens “propriétaire de leurs données et du code utilisé”. Nous lancerons officiellement ce projet dans les semaines à venir. Restez sur la fréquence… Aude, Cyril, Antoine et Olivier.