


POC to obtain your private and free AI with Ollama and PrivateGPT
This article follows my first two articles on similar deployments, namely LM Studio as an inference server (LLM model) with its very restrictive license and then with Jan whose AGPL v3 license is one of the most ethical.
Here we will create this POC with Ollama, which is graciously distributed under the Open Source MIT license. All the information is here: https://ollama.com/
No graphical interface but command line (CLI), although it is entirely possible to install a graphical interface, Web or more comprehensive, for Ollama, thanks to the many projects that offer it. The goal here is to stay minimalist and get the job done with as few components as possible.
I assume you have followed my first article, at least for the theoretical explanations and the basic tools necessary for building this POC (Proof of Concept). Otherwise, I strongly encourage you to do so if you do not already have the required skills in this area!
Technologies required for this POC
- Apple MacBook Pro M2 MAX platform with 32 GB of RAM.
- Homebrew as a package manager for the macOS operating system.
- iTerm2 as the terminal.
- Python 3.11 with Pyenv to manage multiple versions of Python without risking instability on the MacBook.
- Poetry as the package and dependency manager for the Python language.
- Make, a cross-platform tool to automate the compilation and installation of software.
- Ollama, a framework coded in Go (83%) to run LLM models locally. Here we are under the MIT license, so it’s Open Source but with a lot of freedom, including the ability to integrate the code into proprietary code. We love it for its simplicity and the encouragement to innovate that this license provides, but we like it less for the risk of having our code looted by grave robbers, oops, Git repo looters.
- PrivateGPT, the second major component of our POC, along with Ollama, will be our local RAG and our graphical interface in web mode. It provides us with a development framework in generative AI that is private, secure, customizable, and easy to use.
Knowledge required for this POC
In terms of knowledge, no prerequisites other than knowing how to use the command line in a terminal, an editor like Vim or Nano within this terminal, or even VS Code (Visual Studio Code), which is free and very useful if you do a little or a lot of development. It’s a source code editor developed by Microsoft. It is designed to be lightweight yet powerful, offering a comprehensive development experience for developers. Oh yes, some knowledge of Git but again the bare minimum: knowing how to clone a repository, and I’ll provide the commands if it’s new to you.
Let’s go!
As mentioned above, I assume you know how to manage the basic tools necessary for the operation of PrivateGPT (Homebrew, Python, Pyenv, Poetry…) or that you have consulted my first article to deploy them.
Deployment of Components
If you have already deployed LM Studio or Jan, PrivateGPT, HuggingFace_Hub by following my previous articles, then I suggest you create a new branch of your Git to run your tests for Ollama. This is what I will present here.
Creating a New Git Branch for PrivateGPT, Dedicated to Ollama
Navigate to your development directory /private-gpt
Ensure you are in your main branch “main”, your terminal should display the following:
private-gpt git:(main)Otherwise, switch to your main branch with the command:
git checkout mainCreate a new branch suitable for this project with the Ollama framework. In my case, I named it “ollama-local-embeddings” to maintain the logic of my previous two articles.
git checkout -b ollama-local-embeddingsYou are now in your new functional branch, your terminal indicates:
private-gpt git:(ollama-local-embeddings)Take this opportunity to update your Poetry environment if not done recently. At the time of writing this article, I am using version 1.8.3:
poetry self updateVerify the update by checking the Poetry version:
poetry --versionInstallation of Ollama on macOS
Official Ollama website: https://ollama.com
Download the archive for macOS. Unzip it and then install the Ollama application in your applications.
Note that you can also install Ollama with Homebrew, in this case, the command is as follows:
brew install --cask ollamaAt the time I wrote this documentation, we are at version 0.1.46 of Ollama, released on June 20 on its GitHub repository: https://github.com/ollama/ollama
If everything is well installed, just like with LM Studio or Jan from my previous articles, you will already be able to play with a local generative AI on your Mac.
First steps with Ollama and essential commands:
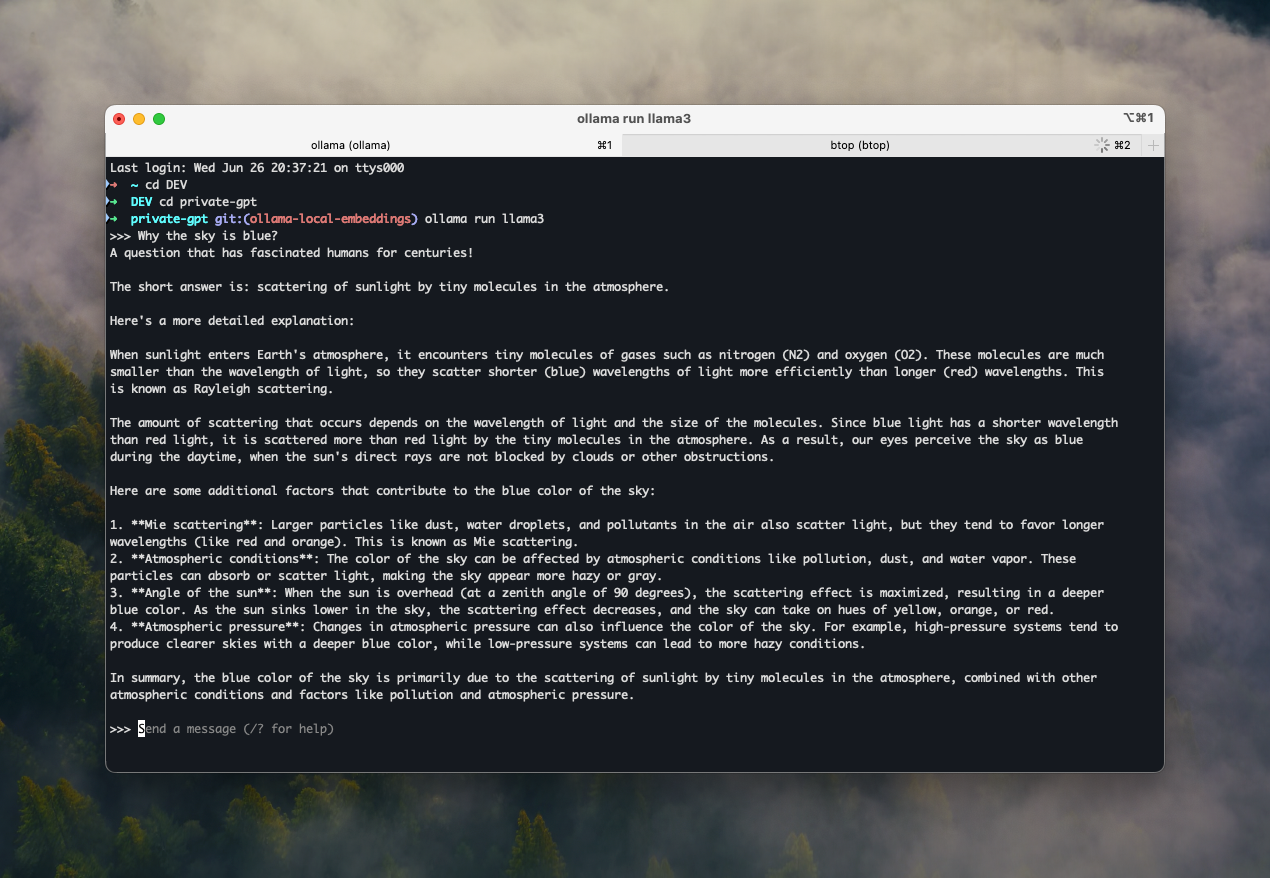
We will check that everything works and download at least the “Llama 3” LLM model to compare with what we have already done together.
Everything that follows takes place in your preferred terminal, in my case I use iTerm2.
Check the installed version:
ollama --version You should get something like:
ollama version is 0.1.46To list your already downloaded or created LLM models in Ollama:
ollama listIf you have just installed Ollama and have not loaded anything, your list will be empty.
Download an LLM model, in our case, we choose the Llama3 model:
ollama pull llama3Launch an LLM model:
ollama run llama3 Note that if you haven’t already downloaded it, it will be downloaded first and then started, and depending on your bandwidth, the download may take a long time!
After a few seconds related to starting your Ollama instance with the loaded LLM model, you will get a prompt similar to this:
>>> Send a message (/? for help)You can test!
To delete a model and free up space:
ollama rm modelnameFor basic information, it’s simple:
/?To switch between your models:
ollama run mistralAnd to exit the command prompt:
/byeLet’s now start the Ollama server:
You can start Ollama with the following command:
ollama serveIf, like me, you installed it from the archive available on the website, your Ollama instance is probably already running, and you will get the following message:
Error: listen tcp 127.0.0.1:11434: bind: address already in use
Let’s easily test if the server is working. To do this, open a web browser and type this:
You should get an “Ollama is running” message at the top left of your browser window like this:

Installation of dependencies for the operation of PrivateGPT with Ollama:
Let’s now install the Poetry dependencies necessary for the proper operation of PrivateGPT with Ollama. Note that the following command will remove the dependencies of our previous POCs with LM Studio and Jan. If you want to keep all three instances operational, then adapt your command to include all the dependencies.
poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"You should see the installation of all the necessary packages for the project running in your terminal.
Some useful explanations about the arguments, located between the double quotes, in this command line:
uito use the Gradio UIllms-ollamato connect to Ollama, which is, if needed to be reminded, a local Open Source LLM under the MIT license.embeddings-ollamato be able to use a model in Ollama locally for vectorizing our documents. These models are used to convert words, phrases, or entire documents into number vectors. These vectors capture semantic aspects of the text, allowing algorithms to work with text using mathematical operations. I will try to write an article later on about what vectors are.vector-stores-qdrantfor storing the created vectors in the Qdrant format.
Configuration of PrivateGPT
We will now modify the configuration file suitable for our POC, namely the settings-ollama.yaml file, which you should find at the root of your private-gpt directory.
To edit the file, in your terminal, I recommend using the nano editor:
nano settings-ollama.yamlserver:
env_name: ${APP_ENV:ollama}
llm:
mode: ollama
max_new_tokens: 512
context_window: 3900
temperature: 0.1 #The temperature of the model. Increasing the temperature will make the model answer more creatively. A value of 0.1 would be more factual. (Default: 0.1)
embedding:
mode: ollama
ollama:
llm_model: llama3
embedding_model: nomic-embed-text
api_base: http://localhost:11434
embedding_api_base: http://localhost:11434 # change if your embedding model runs on another ollama
keep_alive: 5m
tfs_z: 1.0 # Tail free sampling is used to reduce the impact of less probable tokens from the output. A higher value (e.g., 2.0) will reduce the impact more, while a value of 1.0 disables this setting.
top_k: 40 # Reduces the probability of generating nonsense. A higher value (e.g. 100) will give more diverse answers, while a lower value (e.g. 10) will be more conservative. (Default: 40)
top_p: 0.9 # Works together with top-k. A higher value (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text. (Default: 0.9)
repeat_last_n: 64 # Sets how far back for the model to look back to prevent repetition. (Default: 64, 0 = disabled, -1 = num_ctx)
repeat_penalty: 1.2 # Sets how strongly to penalize repetitions. A higher value (e.g., 1.5) will penalize repetitions more strongly, while a lower value (e.g., 0.9) will be more lenient. (Default: 1.1)
request_timeout: 120.0 # Time elapsed until ollama times out the request. Default is 120s. Format is float.
vectorstore:
database: qdrant
qdrant:
path: local_data/private_gpt/qdrantYou will notice that in this test I am no longer using the embedding model BAAI/bge-small-en-v1.5 that I used in my previous two tests but rather the nomic-embed-text model. The reason is very simple, Ollama provides an ingestion engine usable by PrivateGPT, which was not yet offered by PrivateGPT for LM Studio and Jan, but the BAAI/bge-small-en-v1.5 model is not available at Ollama.
We will see in our tests if this changes the quality of the answers provided.
You can of course change LLM models and text embeddings, test other values for temperature, or the maximum number of tokens that the LLM should use.
Loading the embedding model in Ollama:
Earlier we downloaded the LLM model Llama3, but since Ollama will also serve us in the ingestion role to digest our documents and vectorize them with PrivateGPT, we need to download the model we declared in the configuration, namely: nomic-embed-text, with the appropriate command:
ollama pull nomic-embed-textIf you now list your models, you should have at least the following:

"ollama list" command after installing 2 models for this POC:IMPORTANT NOTICE: If you have already followed one of my previous articles about my POCs on LM Studio and Jan, you likely have a Qdrant vector database that is set up for the BAAI/bge-small-en-v1.5 ingestion model we used. The vector dimensions are not the same from one model to another! To clear the Qdrant database, use this command in PrivateGPT:
make wipeWhich should return a result similar to this:
private-gpt git:(ollama-local-embeddings) ✗ make wipe
poetry run python scripts/utils.py wipe
17:46:59.739 [INFO ] private_gpt.settings.settings_loader — Starting application with profiles=[‘default’, ‘ollama’]
— Deleted /Users/netspirit/DEV/private-gpt/local_data/private_gpt/docstore.json
— Deleted /Users/netspirit/DEV/private-gpt/local_data/private_gpt/index_store.json
Collection dropped successfully.Starting PrivateGPT
This is the big moment, if everything has gone well so far, there is no reason it shouldn’t work, suspense…
Still in your private-gpt directory, in the command line, start PrivateGPT with make, note that you will now always need to use this series of commands to start your PrivateGPT instance:
export PGPT_PROFILES=ollama
make runYou can test that the Ollama model is properly loaded for your PrivateGPT with the command:
echo $PGPT_PROFILESWhich should return:
ollamaUsing the PrivateGPT interface and testing the RAG
Connect using your preferred web browser to the address http://localhost:8001
You should see this:
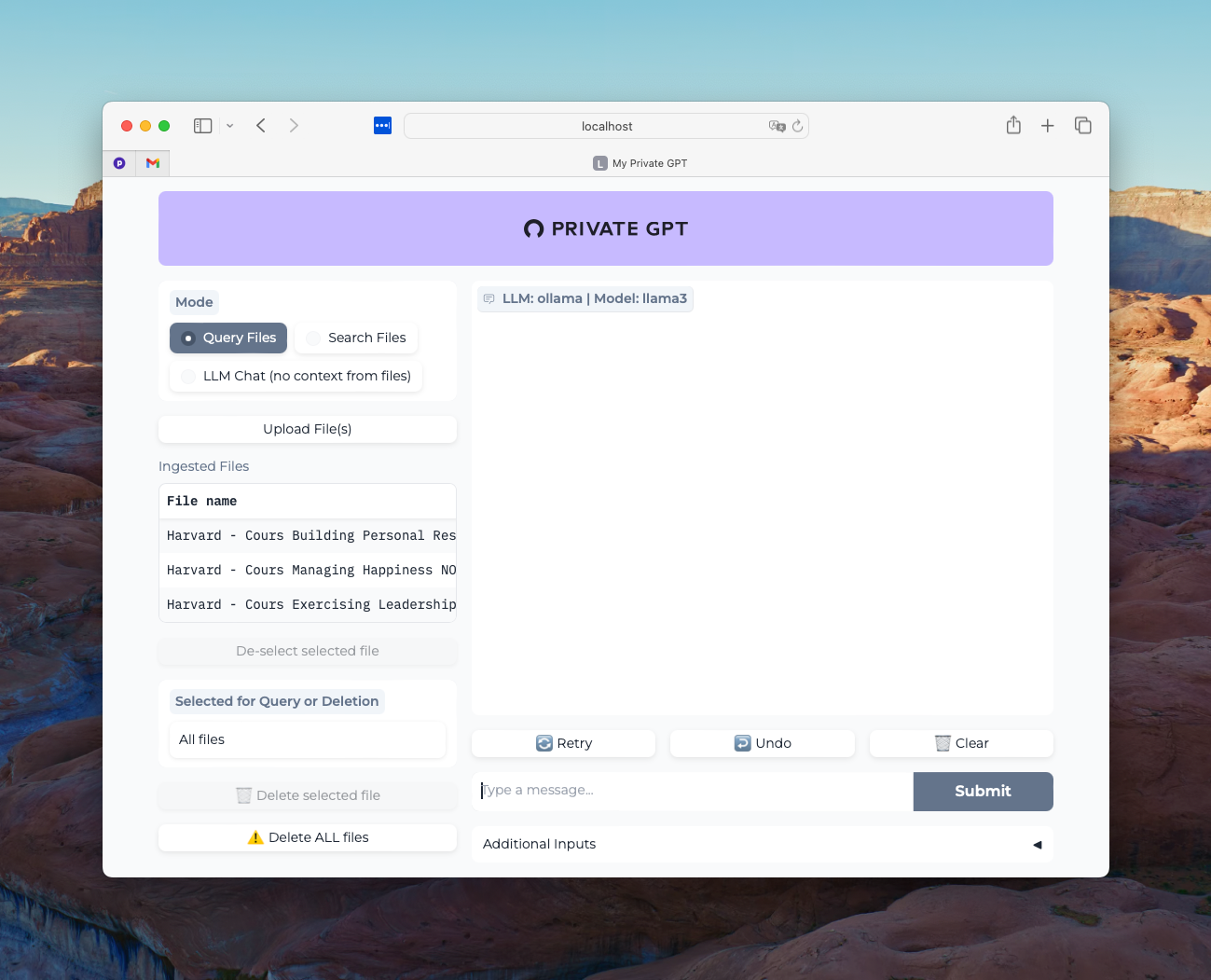
Except that you should not have any files present in the “Ingested Files” column. If you find your files from previous tests here, I invite you to delete them and then rerun the command to clear the contents of your Qdrant vector database:
make wipeFor my tests, I loaded into the RAG notes from my courses dedicated to leadership and mental health improvement, 3 PDF documents totaling approximately 30,000 words, just as I did for LM Studio and Jan.
If, while loading your own files, you get an error similar to:
ValueError: could not broadcast input array from shape (768,) into shape (384,)Then reread the IMPORTANT NOTICE in the chapter “Loading the embedding model in Ollama” :-)
On META’s Llama 3 model, without any fine-tuning, the results are even more impressive than with my previous POCs under LM Studio and Jan. I am still as fast as a ChatGPT 4o.
Have fun comparing queries with the context of your documents (Query Files button activated) versus queries without the context (LLM Chat button activated).
In the following example, after clearing the history, I used the same query but without the context provided by my course notes.
Final test this time with the “Search Files” mode enabled, and I ask the same question. Here we measure the almost instantaneous speed of the response and its relevance (validated with my course notes).
Note that my course notes are in French, so the excerpts chosen by the AI to respond to me will be in French.
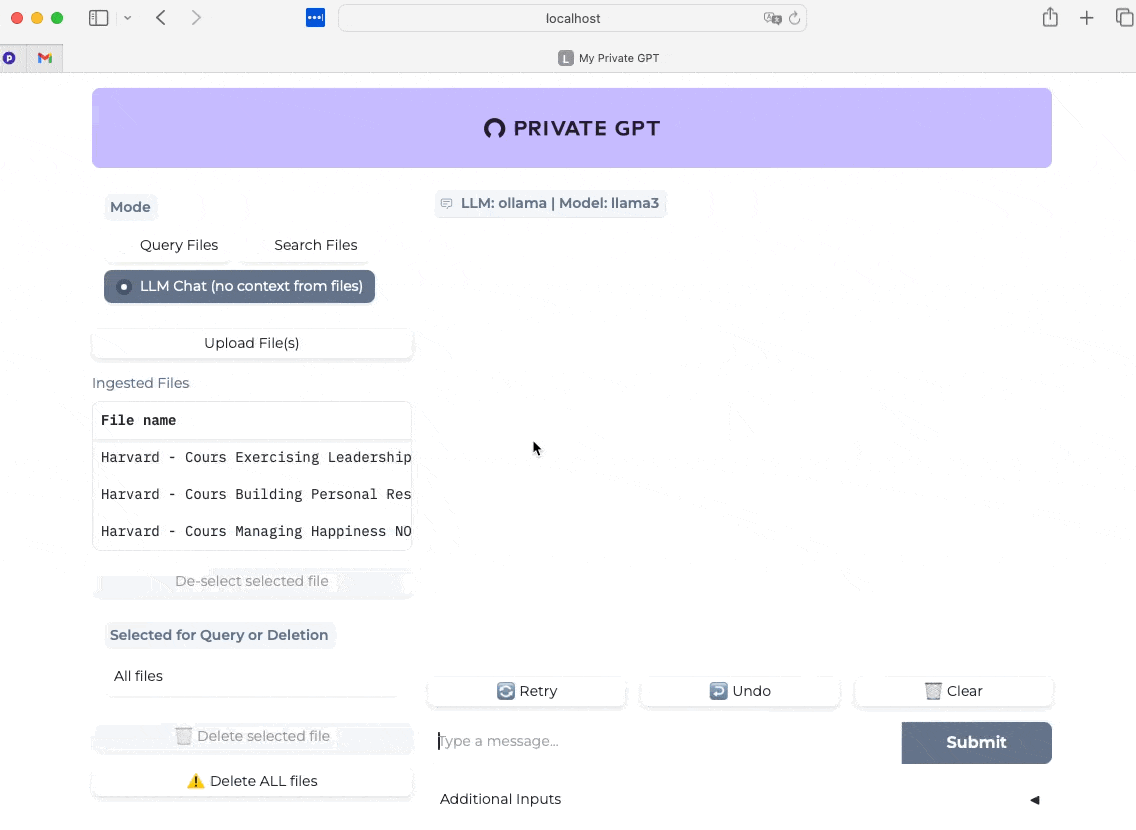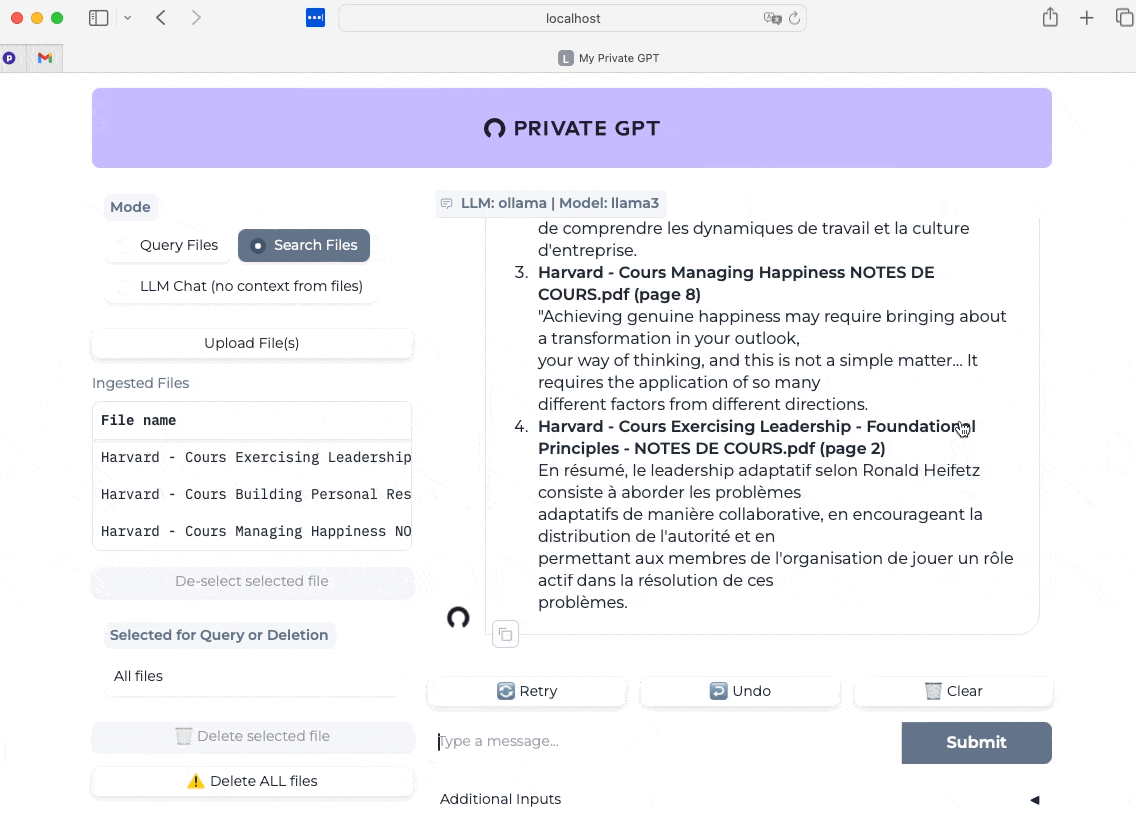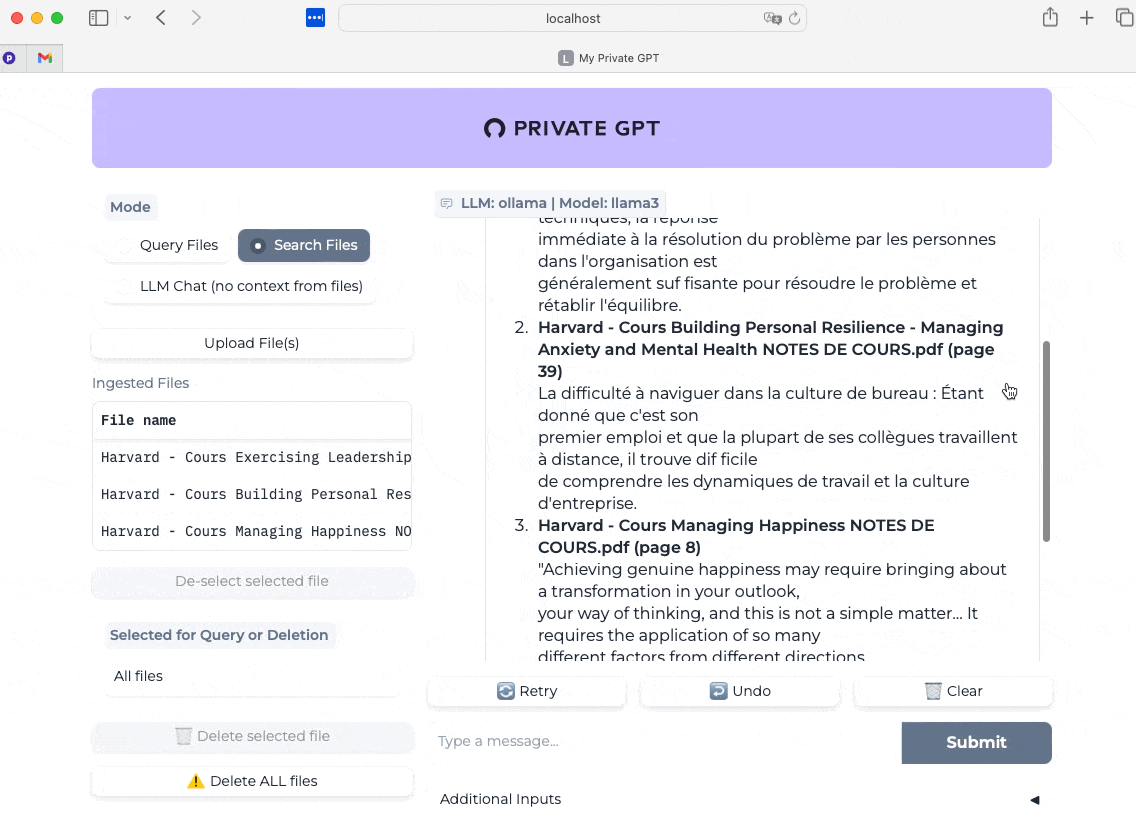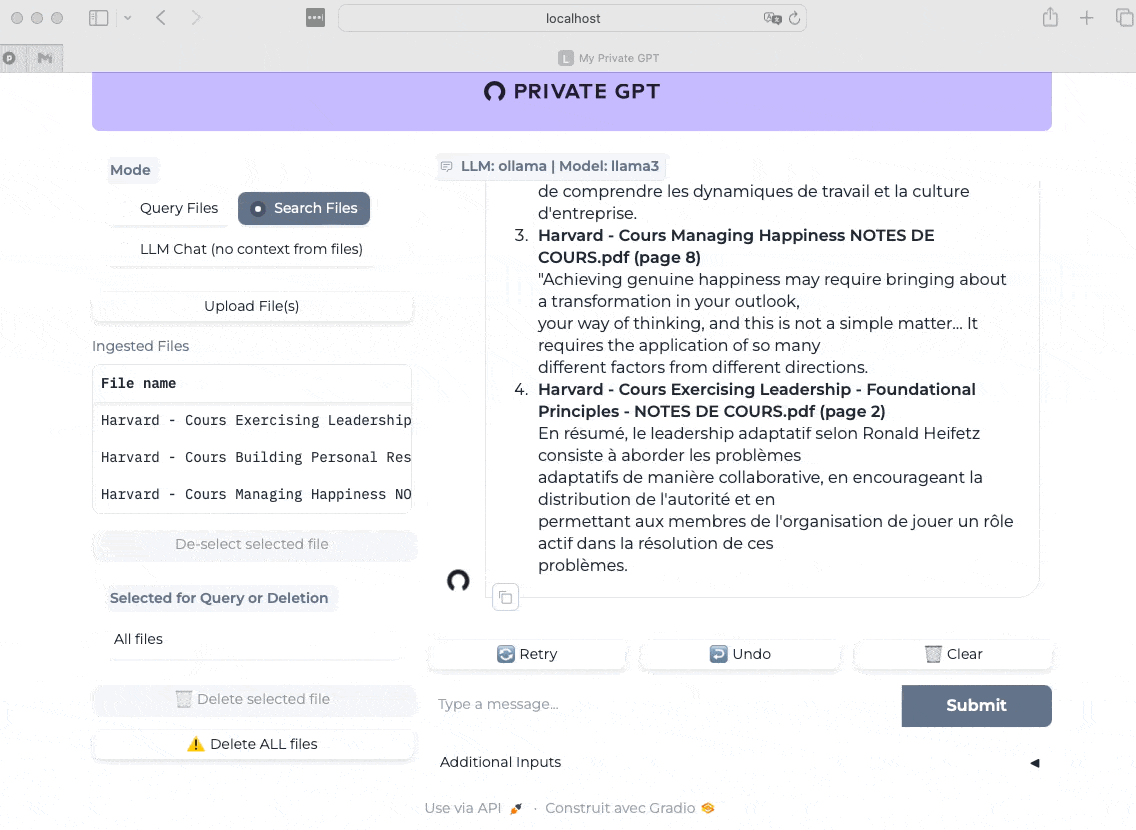
Of course, just like with LM Studio and Jan, or ChatGPT, Claude, Gemini, and others, the most important thing after the technical components is you and your ability to challenge the AI, but that’s another topic ;-)
For the future
A bit of buzz…
It turns out that for several months, I have been working with three colleagues on the development of a local, private, highly secure, minimalist, and Open Source AI solution (at least MIT licensed) for organizations that want to better exploit their data while remaining sovereign in the sense of “owners of their data and the code used”. We will officially launch this project in the coming weeks. Stay tuned… Aude, Cyril, Antoine, and Olivier.